The Complete Guide to Speech Recognition AI in 2025: Tools, APIs, and Developer Insights
A deep dive into speech recognition AI for developers in 2025: explore leading APIs like Whisper, Deepgram, and Google, learn about privacy, real-time processing, and best practices for building robust voice-driven applications.
Introduction to Speech Recognition AI
Speech recognition AI has become a cornerstone of modern computing, enabling machines to interpret and transcribe human speech into text with remarkable accuracy. Leveraging advances in deep learning and natural language processing (NLP), speech recognition AI transforms voice commands, meetings, and conversations into actionable data. Its impact spans diverse sectors such as accessibility, customer service, healthcare, and enterprise automation.
The benefits of speech recognition AI include hands-free interaction, real-time transcription, improved accessibility for users with disabilities, and seamless integration with voice-driven applications. As of 2025, the technology has matured to handle noisy environments, support multiple languages, and offer robust APIs for developers. This guide explores the workings, leading tools, advanced features, and practical integration strategies for speech recognition AI.
How Speech Recognition AI Works
The Speech-to-Text Pipeline
Speech recognition AI systems rely on a structured pipeline to convert raw audio into readable text. This process generally includes:
- Audio Capture: Recording the user’s voice through a microphone or device.
- Audio Preprocessing: Denoising, normalization, and endpoint detection to isolate speech from background sounds.
- Feature Extraction: Transforming audio waves into spectrograms or MFCCs (Mel-Frequency Cepstral Coefficients).
- Inference: Applying neural network models to predict text sequences.
- Post-Processing: Applying language rules, punctuation, and formatting for readable output.
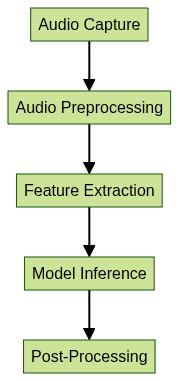
This end-to-end pipeline ensures accurate and context-aware speech-to-text conversion, which is at the heart of all modern voice AI solutions.
Core Technologies Behind Speech Recognition AI
Modern speech recognition AI is powered by deep neural networks trained on massive datasets of diverse speech samples. Core technologies include:
- Acoustic Models: Neural networks that map audio features to phonemes or words.
- Language Models: NLP-driven models predicting word sequences and context for better accuracy.
- End-to-End Deep Learning: Architectures like RNNs, CNNs, and Transformers that process audio directly to text without manual feature engineering.
- Automatic Speech Recognition (ASR): Systems integrating both acoustic and language models to transcribe speech.
NLP plays a crucial role in understanding meaning, handling accents, and adapting to new domains. As AI models evolve, speech recognition systems are becoming more robust, multilingual, and capable of real-time processing. For developers building real-time voice applications, integrating a
Voice SDK
can streamline the process of capturing and transmitting high-quality audio for speech recognition.Leading Speech Recognition AI Tools & APIs
OpenAI Whisper
OpenAI Whisper is a breakthrough open-source speech recognition model, offering:
- Multilingual Support: Recognizes and transcribes speech in dozens of languages.
- Local Processing: Can run on local machines, ideal for privacy-sensitive applications.
- Open Source Flexibility: Customizable and free for community use.
Sample Python Usage:
1import whisper
2model = whisper.load_model("base")
3result = model.transcribe("audio.mp3")
4print(result["text"])
5Whisper’s architecture enables accurate transcription and translation, making it a go-to choice for developers needing a customizable ASR engine. For those looking to add real-time voice features to their applications, leveraging a
Voice SDK
alongside speech recognition models can enhance user experiences with live audio rooms and interactive voice capabilities.Google Speech-to-Text
Google Speech-to-Text is a cloud-based API providing:
- Real-Time Transcription: Low latency, streaming speech-to-text for live applications.
- Extensive Language Support: Recognizes over 100 languages and dialects.
- Scalability and Security: Managed infrastructure with enterprise-grade reliability.
Sample Python Usage:
1from google.cloud import speech_v1p1beta1 as speech
2client = speech.SpeechClient()
3audio = speech.RecognitionAudio(uri="gs://bucket/audio.wav")
4config = speech.RecognitionConfig(language_code="en-US")
5response = client.recognize(config=config, audio=audio)
6for result in response.results:
7 print("Transcript:", result.alternatives[0].transcript)
8Google’s API is widely adopted for cloud-based voice AI, powering applications in customer service, accessibility, and enterprise workflows. When building comprehensive communication platforms, combining speech recognition with a robust
Video Calling API
can enable seamless transitions between voice, video, and text.Deepgram & Other Noteworthy APIs
Deepgram delivers high-accuracy, low-latency speech recognition with:
- Real-Time Streaming: Supports live transcription for calls, meetings, and broadcasts.
- Industry Adoption: Used in call centers, media, and healthcare.
- Developer-Friendly API: Easy integration for fast prototyping and scaling.
Sample Python Usage:
1import deepgram_sdk
2from deepgram_sdk import Deepgram
3import asyncio
4
5deepgram = Deepgram("YOUR_DEEPGRAM_API_KEY")
6async def transcribe():
7 source = {"url": "https://www.example.com/audio.mp3"}
8 response = await deepgram.transcription.prerecorded(source, {"punctuate": True})
9 print(response["results"]["channels"][0]["alternatives"][0]["transcript"])
10asyncio.run(transcribe())
11Other APIs like AssemblyAI, IBM Watson, and Microsoft Azure also offer feature-rich speech APIs suitable for various industry needs. For developers interested in integrating calling features, exploring a
phone call api
can help facilitate seamless voice communication within your applications.Advanced Features of Modern Speech Recognition AI
Diarization and Speaker Identification
Diarization refers to the process of segmenting audio streams into distinct speakers, crucial for meeting transcription, interviews, and analytics. Speaker identification further labels speakers, enabling attribution and context in multi-speaker scenarios. This is vital for creating searchable, actionable transcripts in enterprise and legal domains. By leveraging a
Voice SDK
, developers can easily incorporate features like speaker identification and live audio segmentation into their platforms.Multilingual & Real-Time Capabilities
Modern speech AI can process multiple languages in real time, breaking down language barriers in global meetings, customer support, and online content. Capabilities include translation, live captioning, and instant transcription across dozens of languages, making collaboration and accessibility seamless worldwide. Integrating a
Video Calling API
with speech recognition enables real-time multilingual communication in both audio and video conferencing environments.Privacy, Security, and On-Device Speech Recognition
With increasing privacy concerns and regulations (SOC 2, HIPAA), many solutions offer on-device or local speech recognition. Processing audio locally ensures sensitive data never leaves the device, meeting strict compliance requirements. This is especially important for healthcare, legal, and enterprise applications where data privacy is paramount.
Implementing Speech Recognition AI: Practical Guide
Choosing the Right Speech Recognition AI for Your Needs
Key factors when selecting a speech recognition AI include:
- Accuracy: Evaluate benchmarks and real-world tests.
- Privacy: Consider SOC 2, HIPAA compliance, and on-device options.
- Cost: Cloud APIs may incur per-minute charges; open-source is often free.
- Language Support: Ensure coverage for your target audience.
For developers working with Python, a
python video and audio calling sdk
can be invaluable for building integrated communication solutions that combine speech recognition with real-time audio and video features.Integrating Speech Recognition AI in Applications
Most APIs offer REST or SDK-based integration. Developer considerations include authentication, audio format support, and handling streaming vs. batch modes.
Sample Python Integration:
1import requests
2API_URL = "https://api.speech-to-text.com/v1/transcribe"
3audio_file = open("audio.wav", "rb")
4response = requests.post(
5 API_URL,
6 headers={"Authorization": "Bearer YOUR_API_KEY"},
7 files={"file": audio_file}
8)
9print(response.json()["transcript"])
10Steps:
- Obtain API credentials.
- Prepare and preprocess audio.
- Send audio to the API endpoint.
- Parse and use the returned transcription.
If you're developing in JavaScript, using a
javascript video and audio calling sdk
can help you quickly add real-time communication and speech recognition to your web applications.Handling Noisy Environments and Edge Cases
Robust speech recognition AI employs noise reduction algorithms and endpoint detection to improve accuracy in challenging audio conditions. Preprocessing techniques like spectral gating and automatic gain control further enhance transcription quality. Developers should also account for overlapping speech and crosstalk in real-world scenarios. Utilizing a
Voice SDK
can provide built-in noise suppression and echo cancellation, making it easier to achieve high transcription accuracy even in noisy environments.Optimizing for Accuracy & Performance
Use custom vocabularies and domain-specific model training to boost recognition rates. Fine-tuning models and leveraging hardware acceleration (e.g., GPUs, TPUs) can minimize latency and optimize throughput, especially for real-time applications.
Use Cases and Industry Applications of Speech Recognition AI
Speech recognition AI is revolutionizing workflows in:
- Customer Service: Call transcription, sentiment analysis, and automated QA.
- Accessibility: Real-time captioning for users who are deaf or hard of hearing.
- Healthcare: Clinical dictation, medical documentation, and voice-driven EHRs.
- Meetings & Collaboration: Live transcription, searchable archives, and multilingual support in enterprise tools.
- Voice Interfaces: Smart assistants, IVR systems, and voice-activated IoT devices.
These applications demonstrate the versatility and business value of modern speech-to-text solutions. For organizations looking to experiment with these technologies, you can
Try it for free
and explore how speech recognition AI can be integrated into your workflows.Future of Speech Recognition AI
Looking ahead, speech recognition AI is poised for further innovation:
- Multimodal AI: Integration with vision and text for richer context understanding.
- Edge & Hardware Integration: Running speech models efficiently on mobile, IoT, and embedded devices.
- Ethical & Privacy Concerns: Continued focus on bias reduction, transparency, and secure processing.
Advances in transformer models, federated learning, and open-source collaboration will shape the next generation of voice AI solutions.
Conclusion: Unlocking the Power of Speech Recognition AI
Speech recognition AI is transforming how we interact with technology in 2025. By understanding its core technologies, tools, and implementation strategies, developers can build more accessible, intelligent, and privacy-conscious applications.
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ