Introduction to Speech to Text
Speech to text, also known as speech recognition or voice to text, is the process of converting spoken words into written text using software and hardware. This technology has become increasingly vital in 2025, powering accessibility tools, productivity enhancements, video editing workflows, and more. Whether you need to generate automatic subtitles for videos, create transcriptions for meetings, or control software hands-free, understanding how to do speech to text efficiently is essential for developers and users alike.
There are various methods to achieve speech to text: built-in OS features, online tools, powerful APIs, and custom applications. This guide will walk you through how to do speech to text on different platforms, explore technical underpinnings, and provide best practices for optimal accuracy and efficiency.
Understanding Speech to Text Technology
How Speech Recognition Works
At a high level, speech recognition involves capturing audio input, processing it using digital signal processing (DSP), and converting the sound waves into text via machine learning models, often deep neural networks trained on vast datasets. These models can distinguish phonemes, identify words, and even handle accents or noisy conditions.
Types of Speech to Text Solutions
When learning how to do speech to text, it’s important to know the available solutions:
- Online Tools: Browser-based apps or web APIs that process audio in the cloud (e.g., Google Speech-to-Text API, Web Speech API)
- Offline Solutions: Apps or libraries that work without internet access (e.g., Vosk, Windows built-in speech recognition)
- APIs: Developer-friendly interfaces for integrating speech to text into custom software (e.g., Python SpeechRecognition, Microsoft Azure Speech)
- Built-in OS Tools: Features in Windows, Mac, iOS, and Android for direct speech input
If you're building real-time communication features, consider integrating a
Voice SDK
to enable seamless voice interactions within your applications.Choosing the right approach depends on your requirements for privacy, accuracy, cost, and platform support.
Setting Up for Speech to Text
Preparing Your Hardware and Environment
A high-quality microphone is crucial for accurate speech to text. Choose a unidirectional or noise-cancelling mic to reduce background sounds. Position the microphone away from noisy equipment and use a pop filter if possible. Ensure your recording environment is quiet and free from echo for the best accuracy.
Software Options: Choosing the Best Speech to Text Tool
Depending on your needs, you can choose between free and paid software, as well as online or offline solutions. For Windows, built-in tools and third-party apps like Dragon NaturallySpeaking are popular. On Mac, built-in Dictation or third-party options exist. Linux users may rely on open-source solutions. Browser-based tools (Web Speech API) and mobile apps (Gboard, iOS Dictation) are also widely used. Always consider privacy, language support, and integration capabilities. Developers looking to add video and audio communication features can explore the
javascript video and audio calling sdk
for browser-based projects or thepython video and audio calling sdk
for Python applications.How to Do Speech to Text on Major Platforms
How to Do Speech to Text on Windows
Windows includes a built-in speech recognition tool that makes it straightforward to convert speech to text. Here’s how to do speech to text on Windows:
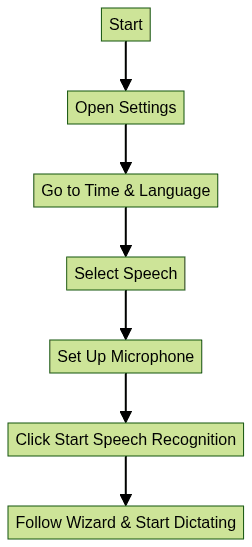
- Open Settings > Time & Language > Speech
- Set up your microphone and run through the wizard
- Click Start Speech Recognition
- Dictate directly into apps like Notepad or Word
For developers targeting Android, understanding
webrtc android
can be beneficial for building robust voice and video communication features.This built-in feature is free and integrates with most Windows applications.
How to Do Speech to Text on Mac
Apple’s macOS offers Dictation, a robust built-in speech to text tool:
- Go to Apple Menu > System Settings > Keyboard
- Enable Dictation
- Choose your preferred language
- Press the Fn key (or your shortcut) to start dictating
- Speak clearly into your microphone—text will appear as you speak
For advanced needs, third-party tools like Dragon for Mac or Otter.ai’s browser solution can add features like transcription management and advanced editing. If you want to add real-time voice features to your Mac applications, integrating a
Voice SDK
can enhance user experience.How to Do Speech to Text Online
Online tools allow you to do speech to text without installing software. A typical workflow involves:
- Visit a service like
text-speech.net
ordictation.io
- Click the microphone icon to start
- Grant browser permission to access your microphone
- Speak clearly—the text appears in real time
- Copy or export your transcript
These tools use APIs like the Web Speech API and are ideal for quick transcriptions or for platforms where installing software isn’t possible. If you need to add video calling capabilities to your web app, consider using a
Video Calling API
for seamless integration.How to Do Speech to Text with Mobile Devices (Android/iOS)
Mobile devices offer built-in and app-based solutions:
- Android: Use Gboard or Google Assistant. Tap the microphone icon on the keyboard and start speaking.
- iOS: Activate Dictation in Settings > General > Keyboard > Enable Dictation. Tap the microphone on the keyboard.
- Apps: Third-party apps like Otter.ai, Speechnotes, and Voice Notes offer advanced features such as automatic punctuation, cloud sync, and exporting.
Both platforms support multiple languages and real-time transcription. For developers, embedding a
Voice SDK
into your mobile app can provide advanced voice communication features.How to Convert Speech to Text for Video Editing (Kdenlive, FCPX)
Modern video editors integrate speech to text for automatic subtitles:
- Kdenlive: Use the built-in speech to text tool (Settings > Configure Kdenlive > Speech to Text). You may need to install Vosk models. Export subtitles as
.srtfiles.
1{
2 "speech_to_text": {
3 "engine": "vosk",
4 "model": "vosk-model-en-us-0.22"
5 }
6}
7- Final Cut Pro X (FCPX): Use third-party plugins like Simon Says or export audio for transcription, then import
.srt/.vttfiles.
If you’re building a custom video editing tool, you can
embed video calling sdk
to enable collaborative editing and real-time communication.Building Your Own Speech to Text App
Using Web Speech API for Browsers
For browser-based projects, the Web Speech API enables real-time speech to text using JavaScript:
1const recognition = new window.SpeechRecognition() || new window.webkitSpeechRecognition();
2recognition.lang = "en-US";
3recognition.interimResults = false;
4recognition.maxAlternatives = 1;
5
6recognition.onresult = function(event) {
7 const transcript = event.results[0][0].transcript;
8 console.log("Transcript:", transcript);
9};
10
11recognition.onerror = function(event) {
12 console.error("Error occurred in recognition:", event.error);
13};
14
15recognition.start();
16This API is supported in Chrome, Edge, and some other browsers. It’s ideal for prototyping and web apps. For more advanced voice features, integrating a
Voice SDK
can help you build scalable and interactive audio experiences.Using Python for Speech to Text
Python’s
speech_recognition library is popular for building speech to text solutions:1import speech_recognition as sr
2
3recognizer = sr.Recognizer()
4with sr.Microphone() as source:
5 print("Say something...")
6 audio = recognizer.listen(source)
7
8try:
9 text = recognizer.recognize_google(audio)
10 print("You said:", text)
11except sr.UnknownValueError:
12 print("Could not understand audio.")
13except sr.RequestError as e:
14 print(f"Could not request results; {e}")
15You can swap out Google for other APIs like Sphinx or Azure and even use prerecorded audio files. This method allows offline and online recognition depending on the recognizer used.
Tips for Improving Speech to Text Accuracy
- Use a quality microphone and record in a quiet space
- Speak clearly and at a steady pace
- Train the system with your voice if supported
- Regularly update models and software for best results
Best Practices and Troubleshooting
Improving Accuracy and Reducing Errors
To get the most accurate results when learning how to do speech to text, address accents by training the software or selecting regional models. Use punctuation commands if supported. Minimize background noise and echo. Regularly calibrate your microphone.
Common Issues and How to Fix Them
- Hardware Issues: Test with another microphone or port
- Software Issues: Restart the app, check for updates, reinstall drivers
- Network Issues: For online tools, ensure stable internet
- Privacy: Review permissions and data handling policies of the tool or API
Proactively addressing these areas will ensure a smoother speech to text experience.
Conclusion: Future of Speech to Text
Speech to text is evolving rapidly in 2025, with advances in AI and real-time processing enabling better accuracy and broader language support. As models become more robust, integrating speech recognition into software will be more accessible. Try out different tools, experiment with APIs, and explore how to do speech to text in your workflows to unlock new levels of productivity and inclusion. If you're ready to enhance your applications with cutting-edge speech and communication features,
Try it for free
today.Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ