Introduction to LLM for Speech-to-Text
Large language models (LLMs) have emerged as a transformative force in natural language processing (NLP) and are now reshaping the field of speech-to-text. LLMs, typically built on deep transformer architectures, have demonstrated remarkable capabilities in understanding, generating, and transcribing human language. Their application to automatic speech recognition (ASR) is revolutionizing how we convert spoken audio into accurate, readable text.
In recent years, advancements such as Whisper by OpenAI, audio-LLM, and LLaMA have pushed the boundaries of what is possible with speech-to-text AI. These models not only improve transcription accuracy but also enable multilingual speech recognition, robust performance across diverse accents and environments, and seamless integration with modern applications. As we move through 2025, the integration of LLM for speech-to-text is central to voice-driven interfaces, accessibility, and real-time communication systems.
How LLMs Power Speech-to-Text Systems
The journey from traditional ASR systems to LLM-based speech-to-text models marks a significant leap in technology. Early ASR models relied heavily on hand-crafted features, statistical models, and phonetic dictionaries. While effective, they struggled with generalization, accents, and noisy environments.
The introduction of LLMs for speech-to-text brought deep learning into the spotlight. LLMs leverage large datasets, sophisticated transformer architectures, and end-to-end training to model the relationship between audio signals and textual representations. This shift enables:
- Contextual Understanding: LLMs capture long-range dependencies in spoken language, improving transcription in complex, multi-turn conversations.
- NLP-Driven Features: Deep contextual embeddings, semantic understanding, and self-attention mechanisms allow for robust speech recognition, even in ambiguous or noisy scenarios.
- Acoustic and Linguistic Fusion: LLMs for speech-to-text blend acoustic signal processing with advanced NLP, enhancing the system's ability to decode and correct errors on the fly.
With the widespread adoption of LLM for speech-to-text, developers can now leverage models that generalize better, offer domain adaptation with minimal retraining, and provide superior performance in multilingual and real-world deployments. As of 2025, these advances mean that voice interfaces, transcription tools, and accessibility solutions are more powerful and accessible than ever. For developers looking to build real-time audio applications, integrating a
Voice SDK
can further streamline the process of adding robust voice features to their products.Popular LLM Architectures for Speech-to-Text
Whisper by OpenAI
Whisper is a state-of-the-art, open-source ASR model developed by OpenAI. It is built on an encoder-decoder transformer architecture, which enables it to process raw audio inputs and generate accurate transcriptions across multiple languages. The architecture consists of:
- Audio Encoder: Processes input audio waveforms into feature representations.
- Text Decoder: Generates text tokens conditioned on the audio features.
- Multilingual Support: Whisper is trained on a diverse corpus, enabling robust performance across dozens of languages and dialects.
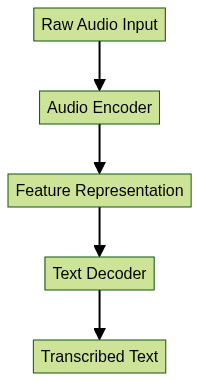
This workflow allows Whisper to function as both a general-purpose and domain-adaptable ASR system, making it a popular choice among developers seeking an LLM for speech-to-text. For those aiming to build comprehensive communication platforms, integrating a
Video Calling API
alongside speech-to-text models can enable seamless video and audio interactions.LLaMA and LLaSE-G1 for Speech Enhancement
Meta's LLaMA and the specialized LLaSE-G1 architecture introduce innovations in generalization and acoustic consistency. LLaSE-G1, in particular, is designed for speech enhancement, addressing challenges such as noisy environments and speaker variability. These models improve the robustness and clarity of transcriptions, contributing significantly to LLM-based audio processing pipelines. Additionally, leveraging a
Live Streaming API SDK
can help developers deliver real-time, interactive audio and video experiences powered by advanced speech-to-text capabilities.Audio-LLM
Audio-LLM models expand the capabilities of LLMs by integrating audio modality directly into the language modeling process. They support hybrid auto-regressive (AR) and non-auto-regressive (NAR) decoding, enabling faster and more flexible transcription workflows. Audio-LLMs also offer improved handling of decoding repetition and generalization, making them suitable for real-time and large-scale speech-to-text applications. For businesses needing to integrate telephony, a
phone call api
can complement LLM-based transcription by enabling direct phone call functionality within applications.Implementation: Using LLMs for Speech-to-Text
Getting Started with Whisper
One of the fastest ways to implement LLM for speech-to-text is by using Whisper in Python. The following code snippet demonstrates installation and basic transcription:
1# Install whisper using pip
2!pip install openai-whisper
3
4import whisper
5model = whisper.load_model("base")
6result = model.transcribe("audio_sample.wav")
7print(result["text"])
8This simple integration provides high transcription accuracy out of the box and can be extended for multilingual and domain-specific use cases. Developers working with Python can accelerate their projects by exploring a
python video and audio calling sdk
for seamless integration of audio and video communication features.Integrating LLMs with Custom Applications
LLMs for speech-to-text can be deployed via APIs, containerized services, or integrated into cloud-native architectures. For scalable deployment:
- API-based Integration: Use REST or gRPC APIs to interact with LLM ASR services from web or mobile apps.
- Batch and Real-Time Processing: Containerize the ASR models (e.g., with Docker) for deployment on Kubernetes or serverless platforms.
- Edge Deployment: Optimize and quantize models for on-device inference, enabling privacy-preserving and low-latency transcription.
Example API usage in Python:
1import requests
2
3def transcribe_audio(file_path, api_endpoint):
4 with open(file_path, "rb") as audio_file:
5 response = requests.post(api_endpoint, files={"audio": audio_file})
6 return response.json()["transcription"]
7
8api_url = "https://api.example.com/v1/asr"
9print(transcribe_audio("meeting_recording.wav", api_url))
10For teams looking to quickly add communication features to their web or mobile platforms, an
embed video calling sdk
can drastically reduce development time and complexity.Challenges in Implementation
While LLM for speech-to-text models are powerful, several challenges persist:
- Acoustic Inconsistency: Environmental noise, microphone quality, and accent variability can impact transcription accuracy.
- Repetition and Decoding Errors: Some transformer models may produce repeated or hallucinated text, requiring post-processing or decoding strategies.
- Language Support: Although multilingual, some LLMs may underperform on low-resource languages or domain-specific jargon.
Careful benchmarking, data augmentation, and model fine-tuning are essential for overcoming these challenges in production deployments. Leveraging a
Voice SDK
can help address some of these challenges by providing optimized audio capture and processing tools for your applications.Benchmarking and Evaluating LLM Speech-to-Text Models
Evaluating LLM for speech-to-text systems involves several key metrics:
- Character Error Rate (CER): Measures the percentage of character-level transcription errors.
- Word Error Rate (WER): Evaluates word-level accuracy, the primary benchmark for ASR models.
- Robustness to Noise: Assesses how well the model performs under adverse acoustic conditions.
- Multilingual Accuracy: Gauges effectiveness across different languages and scripts.
Recent studies (Audio-LLM, LLaSE-G1) highlight improvements in transcription accuracy, generalization, and noise robustness. The following table compares major LLM-based ASR models:
| Model | WER (English) | Multilingual | Noise Robustness | Decoding Approach |
|---|---|---|---|---|
| Whisper | 4.2% | Yes | High | AR Transformer |
| Audio-LLM | 4.8% | Yes | Very High | Hybrid AR/NAR |
| LLaSE-G1 | 5.1% | Limited | Highest | AR + Speech Enhance |
These benchmarks are indicative and should be validated with domain-specific datasets for accurate assessment. For developers seeking to optimize their audio experiences, integrating a
Voice SDK
can further enhance real-time communication and transcription quality.Key Use Cases and Applications for LLM for Speech-to-Text
The integration of LLM for speech-to-text has enabled a new generation of voice-enabled applications:
- Voice Interfaces: Virtual assistants, smart speakers, and voice-driven UIs leverage LLM ASR for natural interactions.
- Customer Support: Contact centers use real-time transcription for call analytics, sentiment analysis, and customer engagement.
- Transcription Services: Automated meeting notes, legal transcripts, and media subtitling benefit from high transcription accuracy and speed.
- Multilingual and Accessibility Solutions: LLM-based ASR unlocks accessibility for users with disabilities and supports global communication through multilingual transcription.
Real-World Example:
A global enterprise deploys Whisper on Kubernetes to provide real-time, multilingual transcription for virtual meetings, enhancing accessibility and compliance across regions. To further streamline voice-driven workflows, organizations can leverage a
Voice SDK
for scalable, high-quality audio integration.Future Directions and Research Opportunities in LLM for Speech-to-Text
Looking ahead to 2025 and beyond, several research avenues promise further advancement for LLM for speech-to-text:
- Next-Generation Architectures: Research into larger, more efficient transformer models, multimodal LLMs, and low-latency decoding continues to accelerate.
- Generalization and Adaptation: Improving performance on low-resource languages, domain-specific tasks, and edge devices remains a focus.
- Open Problems: Addressing repetition in decoding, enhancing robustness to adversarial noise, and reducing compute requirements are key challenges for the community.
Open-source initiatives and collaborative research are vital for pushing the boundaries of LLM-based speech-to-text systems and democratizing access to high-quality ASR.
Conclusion
Large language models are redefining the landscape of speech-to-text. With advances from Whisper, Audio-LLM, and LLaMA, developers now have access to highly accurate, adaptable, and multilingual ASR tools. As research and open-source projects continue to evolve, LLM for speech-to-text will remain essential for powering next-generation voice interfaces, accessibility, and global communication in 2025 and beyond. If you're ready to explore these technologies for your own projects,
Try it for free
and start building with the latest in speech-to-text and communication APIs.Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ