Introduction to Google Speech Recognition API
Speech recognition technology has rapidly evolved in recent years, transforming how we interact with computers, mobile devices, and cloud platforms. By enabling machines to transcribe and interpret human speech, developers can build more accessible, responsive, and intelligent applications. In 2025, the Google Speech Recognition API stands out as one of the most robust solutions for converting spoken audio into accurate, real-time text.
Google Speech Recognition API integrates cutting-edge AI speech models and supports a broad array of integration methods. Whether it’s powering voice assistants, automating transcription workflows, or enhancing accessibility, Google’s API makes high-quality speech-to-text conversion accessible to developers worldwide.
What is the Google Speech Recognition API?
The Google Speech Recognition API is a cloud-based service that enables developers to transcribe audio to text using advanced AI models. Its key features include support for over 125 languages and variants, real-time and batch transcription, and customizable speech adaptation. In 2025, Google’s Chirp model—an advanced large speech model—offers even greater accuracy and speed.
Key Features
- Real-time and batch transcription for streaming or pre-recorded audio
- Global language support with dialect detection
- Custom speech models for domain-specific accuracy
- Security compliance and robust data privacy controls
Use Cases
- Applications: Voice command apps, accessibility tools, and real-time captioning
- Voice Assistants: Integrate voice-based user interfaces in smart devices
- Transcription Services: Automate large-scale audio transcription for media, legal, and educational content
For developers interested in building interactive voice experiences, integrating a
Voice SDK
can further enhance real-time communication features within your applications.The Google Speech Recognition API’s flexibility and scalability make it suitable for startups, enterprises, and hobbyist developers around the globe.
How Does Google Speech Recognition API Work?
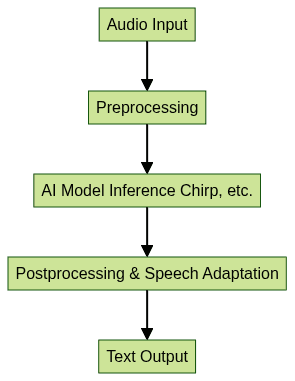
The Google Speech Recognition API leverages powerful AI models to convert spoken audio into text with high accuracy. The speech-to-text process involves several steps:
- Audio Input: Raw audio is captured from a device or uploaded to the cloud.
- Preprocessing: The audio signal is cleaned and prepared for analysis.
- Model Inference: Google’s AI models—like the Chirp model—analyze the audio, recognize phonetic patterns, and map them to text.
- Postprocessing: Output is refined, optionally adapted using custom resources or phrase hints.
- Text Output: The transcribed text is delivered to the application or user.
If you’re developing mobile or web applications that require real-time audio and video capabilities, consider leveraging
webrtc android
andflutter webrtc
solutions for seamless, cross-platform communication.AI Speech Models
- Chirp Model: Google’s latest large speech model, designed for higher transcription accuracy and broader language support.
- Pretrained Models: Models optimized for general and domain-specific speech.
- Customizable Models: Developers can adapt models using class tokens and custom phrase sets.
Speech-to-Text Workflow Diagram
Setting Up Google Speech Recognition API
Prerequisites and Getting Started
To start using the Google Speech Recognition API, follow these steps:
- Create a Google Cloud Project
- Visit the
Google Cloud Console
and create a new project dedicated to your speech applications.
- Visit the
- Enable the Speech-to-Text API
- In the Cloud Console, navigate to "APIs & Services" > "Library" and enable the "Cloud Speech-to-Text API" for your project.
- Free Credits and Pricing Overview
- New users receive $300 in free credits. Pricing is based on audio duration, features used (e.g., enhanced models), and quotas. Refer to the
pricing page
for up-to-date rates in 2025.
- New users receive $300 in free credits. Pricing is based on audio duration, features used (e.g., enhanced models), and quotas. Refer to the
If your application requires integrating voice communication features such as phone calls, you might also explore a
phone call api
to complement your speech recognition workflows.Authentication and Security Compliance
API Authentication
Google Speech Recognition API requires authentication to secure your application:
- Service Accounts: Use JSON key files for server-to-server communication.
- OAuth 2.0: For apps needing delegated user access.
Security Features
- Encryption: All data (in-transit and at-rest) is encrypted using industry standards.
- Data Residency: Choose cloud regions to comply with organizational or regulatory requirements.
- Access Control: Fine-grained IAM roles to manage API usage and permissions.
Integration Methods: REST, gRPC, and Client Libraries
The Google Speech Recognition API offers flexible integration options to suit different development needs.
For developers working with web applications, integrating a
javascript video and audio calling sdk
can provide robust, real-time communication alongside your speech-to-text features.REST API Integration
The REST API is ideal for quick, stateless transcription requests. Here’s how to send a transcription request using
curl:1curl -X POST \
2 -H \"Authorization: Bearer $(gcloud auth application-default print-access-token)\" \
3 -H \"Content-Type: application/json\" \
4 https://speech.googleapis.com/v1/speech:recognize \
5 -d '{
6 "config": {
7 "encoding": "LINEAR16",
8 "sampleRateHertz": 16000,
9 "languageCode": "en-US"
10 },
11 "audio": {
12 "uri": "gs://your-bucket/audio.wav"
13 }
14 }'
15gRPC API Integration
The gRPC API is optimal for low-latency, high-throughput, or streaming use cases (e.g., live voice transcription):
- Streaming: Real-time audio transcription with minimal delay
- Non-Streaming: Batch transcription for pre-recorded audio files
If your project involves live audio rooms or group conversations, integrating a
Voice SDK
can help you build scalable, interactive voice experiences.Example: gRPC Streaming Transcription (Python)
1import grpc
2from google.cloud import speech_v1p1beta1 as speech
3
4client = speech.SpeechClient()
5config = speech.RecognitionConfig(
6 encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
7 sample_rate_hertz=16000,
8 language_code=\"en-US\"
9)
10streaming_config = speech.StreamingRecognitionConfig(config=config)
11
12def audio_generator():
13 with open(\"audio.wav\", 'rb') as f:
14 while chunk := f.read(4096):
15 yield speech.StreamingRecognizeRequest(audio_content=chunk)
16
17requests = audio_generator()
18responses = client.streaming_recognize(streaming_config, requests)
19for response in responses:
20 for result in response.results:
21 print(\"Transcript: {}\".format(result.alternatives[0].transcript))
22Client Libraries
Google provides official client libraries for Python, Java, Node.js, Go, and other major languages.
For mobile and cross-platform apps, you can enhance your solution by integrating a
Voice SDK
to enable real-time voice communication features.Example: Python Client Library
1from google.cloud import speech_v1p1beta1 as speech
2client = speech.SpeechClient()
3
4audio = speech.RecognitionAudio(uri=\"gs://your-bucket/audio.wav\")
5config = speech.RecognitionConfig(
6 encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
7 sample_rate_hertz=16000,
8 language_code=\"en-US\"
9)
10response = client.recognize(config=config, audio=audio)
11for result in response.results:
12 print(\"Transcript: {}\".format(result.alternatives[0].transcript))
13These libraries simplify authentication, error handling, and response parsing, accelerating development and integration.
If you’re looking to add phone calling capabilities to your app, integrating a
phone call api
can streamline voice communication alongside speech recognition.Advanced Features and Customization
Real-time and Batch Transcription
The Google Speech Recognition API supports both streaming (real-time) and batch (long audio files) transcription. Use streaming for interactive applications requiring low latency, and batch mode for large files or offline processing.
For developers building collaborative or interactive audio applications, a
Voice SDK
can be a valuable addition to enable seamless live audio rooms and group conversations.Custom Models and Speech Adaptation
Developers can tailor recognition accuracy using:
- Class Tokens: Guide the model to expect specific data types (e.g., addresses, dates)
- Phrase Sets: Inject domain-specific vocabulary to improve recognition of jargon or brand names
- Custom Resources: Manage and update adaptation resources via the API for evolving requirements
This flexibility is especially valuable in specialized industries, such as healthcare or legal transcription, where unique vocabulary is common.
Best Practices for Using Google Speech Recognition API
To maximize transcription accuracy and system reliability:
- Optimize Audio Quality: Use high-fidelity microphones and minimize background noise
- Select the Right Model: Choose between standard, enhanced, or Chirp models based on your use case
- Configure Appropriately: Adjust sample rates, encoding types, and language codes to match your audio
- Error Handling: Implement robust error handling and manage API quotas proactively to avoid disruptions
By following these best practices, developers can deliver superior user experiences and reduce operational issues.
Limitations and Considerations
Before integrating Google Speech Recognition API, consider the following:
- Audio Duration/File Size: Streaming audio is limited to about 5 minutes, batch requests up to several hours (subject to quotas)
- Supported Formats: Supported encodings include LINEAR16, FLAC, AMR, and more
- Regional Availability: Some features or models may only be available in specific Google Cloud regions
Careful planning ensures compliance and optimal performance for your application’s needs.
Conclusion: Is Google Speech Recognition API Right for You?
The Google Speech Recognition API offers industry-leading accuracy, extensive language support, and flexible integration options. Whether you’re building voice-enabled apps, automating transcription, or enhancing accessibility, it’s a compelling solution in 2025. For specialized needs or unique compliance requirements, evaluate alternatives, but for most developers, Google’s API delivers powerful, scalable speech-to-text capabilities.
Ready to enhance your application with advanced voice features?
Try it for free
and start building with the latest speech recognition and communication tools today.FAQ