Google LLM for Voice: Building the Future of Audio AI with Gemini, AudioLM, and SoundStorm (2025)
Explore the technical evolution of Google LLM for voice, including Gemini, AudioLM, SoundStorm, and hands-on developer integration. Learn use cases, architecture, and the future of AI-powered voice apps in 2025.
Introduction: The Rise of Google LLM for Voice
The landscape of voice technology is undergoing a fundamental transformation in 2025, driven by large language models (LLMs) for voice. Google LLM for voice has emerged as a leader in this space, leveraging state-of-the-art AI to create seamless, nuanced, and multimodal audio interactions. From real-time voice assistants to automatic speech translation and creative content generation, Google's advancements are reshaping how developers build and users experience voice-driven applications. As we explore the current and future capabilities of Google LLM for voice, it is clear that the boundaries between text, speech, and meaning are being redefined by cutting-edge models such as Gemini, AudioLM, AudioPaLM, and SoundStorm.
Understanding Google LLM for Voice: Core Concepts
What is a Large Language Model for Voice?
A large language model (LLM) for voice is an AI system that processes, understands, and generates human-like speech using deep neural networks. Traditional LLMs have excelled at text-based tasks, but Google LLM for voice extends these capabilities to audio, enabling models to handle spoken language, intonation, context, and emotion. For developers looking to integrate advanced voice features into their applications, leveraging a
Voice SDK
can streamline the process and provide robust audio capabilities.Google’s Multimodal Approach: Gemini, AudioLM, and AudioPaLM
Google’s multimodal AI strategy integrates text, audio, and even visual signals. Gemini, Google’s flagship model, natively handles both text and audio, while specialized models like AudioLM and AudioPaLM focus on audio tokenization, speech-to-speech translation, and nuanced audio generation. This multimodal approach enables robust voice recognition, real-time dialog, and cross-lingual communication. Developers interested in implementing real-time audio and video features can also explore solutions like an
embed video calling sdk
for seamless integration.The Role of Neural Audio Codecs: SoundStream and EnCodec
Efficient audio processing requires transforming raw waveforms into compact, expressive representations. Google uses neural audio codecs such as SoundStream and EnCodec, which compress and reconstruct audio without sacrificing quality. These codecs enable fast, scalable, and high-fidelity voice generation and recognition, forming the backbone of Google LLM for voice systems. For applications requiring both audio and video communication, utilizing a
Video Calling API
can enhance user experience and provide additional flexibility.Gemini 2.5: Transforming Voice Interaction
Gemini’s Native Audio Dialog and Generation Features
Gemini 2.5 represents the cutting edge of Google LLM for voice, with native support for audio dialog and generation. The model is designed to handle back-and-forth conversations, audio overviews, and real-time, natural interactions. Whether summarizing meetings, answering questions, or generating expressive speech, Gemini’s audio-first architecture sets a new bar for multimodal AI. For developers building interactive voice experiences, integrating a
Voice SDK
can accelerate development and ensure high-quality audio interactions.Real-Time, Nuanced Conversation with AI
With Gemini 2.5, users experience fluid, responsive conversations with AI. The model captures context, intonation, and even speaker emotion, delivering responses that feel truly human. Thanks to advances in neural audio codecs and parallel processing, latency is minimized, enabling real-time audio dialog in applications like digital assistants and hands-free interfaces. If your application requires phone-based communication, leveraging a
phone call api
can provide reliable and scalable voice calling features.Use Cases: NotebookLM Audio Overviews, Project Astra
- NotebookLM Audio Overviews: Gemini powers automatic audio summarization of documents and meetings, providing concise spoken briefs on demand.
- Project Astra: Demonstrates real-time, interactive dialog with multimodal AI, enabling hands-free information retrieval and support. For projects requiring real-time audio rooms, a
Voice SDK
can be an essential tool for enabling seamless group conversations.
How Gemini’s Audio Pipeline Works
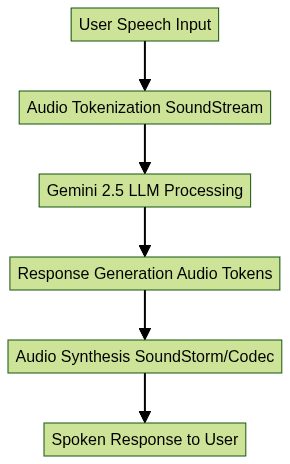
Google’s Audio Generation Models: AudioLM, SoundStorm, and AudioPaLM
AudioLM: Language Modeling for Audio Tokens
AudioLM is Google’s pioneering model for language modeling on audio tokens. Instead of manipulating raw waveforms, AudioLM tokenizes audio into discrete units, allowing the model to predict and generate audio sequences with context and coherence. This approach brings the power of traditional language models to speech and audio generation. Developers working with Python can leverage a
python video and audio calling sdk
to build sophisticated audio and video applications that complement these AI advancements.SoundStorm: Efficient, Parallel Audio Generation
SoundStorm builds on AudioLM, introducing a parallel generation mechanism that accelerates audio synthesis while preserving quality. By leveraging neural audio codecs and fine-grained audio tokens, SoundStorm can generate long, coherent speech segments much faster than previous models, making it ideal for real-time applications. If you're developing cross-platform apps, integrating a
flutter video and audio calling api
can help you deliver seamless audio and video experiences on mobile devices.AudioPaLM: Unified Text-Speech Understanding and Translation
AudioPaLM merges the strengths of text and audio processing, enabling end-to-end speech understanding, translation, and synthesis. It supports direct speech-to-speech translation, zero-shot voice conversion, and cross-lingual dialog, opening new possibilities for global communication and accessibility.
Comparison Table: AudioLM vs. SoundStorm vs. AudioPaLM
| Model | Key Functionality | Audio Tokenization | Real-Time Generation | Translation Support |
|---|---|---|---|---|
| AudioLM | Audio token modeling and synthesis | Yes | Moderate | No |
| SoundStorm | Fast, parallel audio generation | Yes | High | No |
| AudioPaLM | Text-audio unification, translation | Yes | High | Yes (speech-to-speech) |
Code Snippet: Audio Tokenization with Python
Below is an example illustrating how audio tokenization is performed using a neural audio codec. This is a simplified representation:
1import soundstream
2import numpy as np
3
4# Load raw audio waveform (as numpy array)
5audio_waveform = np.load("audio_sample.npy")
6
7# Initialize SoundStream codec
8codec = soundstream.SoundStreamCodec()
9
10# Encode audio to tokens
11audio_tokens = codec.encode(audio_waveform)
12
13print(f"Tokenized audio: {audio_tokens}")
14Practical Implementation: Building Voice Apps with Google LLM
Using Gemini API for Speech Generation
Google provides developers with the Gemini API, which allows seamless integration of google llm for voice into voice-enabled applications. With native endpoints for speech generation, recognition, and dialog, the API abstracts the complexity of model inference and hardware acceleration. For those looking to quickly deploy live audio rooms or interactive voice features, a
Voice SDK
offers an efficient and scalable solution.Integrating with Google Cloud Text-to-Speech
Google Cloud Text-to-Speech offers additional features for customizing voices, languages, and prosody. By combining Gemini’s intelligence with Google Cloud’s scalable infrastructure, developers can build robust, production-grade voice applications, from AI-powered podcasts to accessibility tools.
Step-by-Step: Creating a Podcast or Audio Summary App
- Collect Content: Gather text or audio content to summarize or convert to speech.
- Summarize with Gemini: Use Gemini’s LLM endpoint to generate summaries or scripts.
- Generate Speech: Pass the output to Google Cloud Text-to-Speech or Gemini’s audio endpoint.
- Customize Voice: Select language, accent, speaker identity, and prosody.
- Distribute Audio: Publish the generated audio to podcast platforms or embed in web/mobile apps.
If you want to experiment with these features and build your own voice-enabled application, you can
Try it for free
and start integrating advanced audio capabilities today.Customization: Voice Selection, Language, Speaker Identity
Google LLM for voice supports:
- Multiple languages and dialects
- Choice of male/female/neutral voices
- Custom speaker IDs and voice cloning (for branded personas)
- Prosody control for expressive speech
Code Snippet: Using Gemini API for Text-to-Speech
Below is an example using Python to generate speech from text with Gemini API:
1import requests
2
3API_KEY = "YOUR_GEMINI_API_KEY"
4ENDPOINT = "https://api.gemini.google.com/v1/speech:generate"
5
6payload = {
7 "text": "Welcome to the future of AI voice technology with Google LLM for voice in 2025!",
8 "voice": {
9 "languageCode": "en-US",
10 "name": "en-US-Wavenet-F"
11 },
12 "audioConfig": {
13 "speakingRate": 1.0,
14 "pitch": 0.0
15 }
16}
17headers = {
18 "Authorization": f"Bearer {API_KEY}",
19 "Content-Type": "application/json"
20}
21
22response = requests.post(ENDPOINT, json=payload, headers=headers)
23
24if response.status_code == 200:
25 with open("output_audio.mp3", "wb") as f:
26 f.write(response.content)
27 print("Audio generated successfully.")
28else:
29 print(f"Error: {response.status_code} - {response.text}")
30Opportunities and Challenges in Google LLM for Voice
Multilingual Support and Zero-Shot Translation
Google llm for voice is breaking barriers with multilingual and zero-shot translation capabilities. Developers can build applications that instantly translate and synthesize speech between dozens of languages, unlocking global communication and accessibility. For those building collaborative or social audio experiences, integrating a
Voice SDK
can help facilitate real-time multilingual conversations.Speaker Identity, Prosody, and Voice Cloning
Advanced models enable:
- Accurate speaker identification
- Prosody modeling for natural intonation
- Voice cloning for custom, branded voices
These features drive innovation in audio content creation, podcasting, and digital assistants, but also raise new technical and ethical challenges.
Ethical Considerations and Responsible AI Use
With great power comes responsibility. Google emphasizes transparency, consent, and watermarking for generated audio. Developers should consider:
- Preventing misuse of voice cloning
- Respecting privacy and copyright
- Ensuring fairness and inclusivity in voice AI outputs
The Future of Voice AI: Google’s Roadmap
Upcoming Research and Features
Google’s roadmap for google llm for voice includes:
- Even more natural, expressive, and context-aware voice generation
- Enhanced multimodal dialog, blending voice, text, and visual cues
- Improved real-time translation and accessibility features
Impact on Digital Assistants, Accessibility, and Content Creation
These advances will:
- Make digital assistants more conversational and helpful
- Empower content creators with new audio formats
- Enhance accessibility for users with diverse needs
Conclusion
Google LLM for voice is revolutionizing how we interact with technology, enabling real-time, natural voice interfaces for a new era of computing. As Gemini, AudioLM, SoundStorm, and AudioPaLM mature, developers have unprecedented tools for building expressive, multilingual, and accessible voice applications. The future of voice AI is here—let’s start building.
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ