Introduction to Automatic Speech Recognition Software
Automatic Speech Recognition (ASR) software, often referred to as speech to text or voice recognition technology, has become an essential component in modern digital workflows. By converting spoken language into written text, ASR systems enable a wide range of applications—from real-time transcription in meetings to voice commands in software development environments.
In 2025, the evolution of AI transcription, machine learning, and natural language processing has driven ASR accuracy and accessibility to unprecedented levels. Developers, content creators, and enterprises now rely on ASR for multi-language transcription, accessibility enhancements, and efficient content repurposing. Let's delve into how automatic speech recognition software works, its core features, leading solutions, and best practices for integration in technical workflows.
How Automatic Speech Recognition Software Works
At the core of automatic speech recognition software lies a combination of artificial intelligence, machine learning, and neural network architectures. These systems analyze audio waveforms, extract linguistic features, and map them to textual data using complex algorithms.
Modern ASR leverages deep learning models—such as recurrent neural networks (RNNs) and transformers—to handle diverse accents, languages, and noisy environments. Training these models involves vast datasets of annotated speech, enabling the software to continually improve recognition accuracy.
Cloud-based ASR solutions offer scalable compute resources for batch and real-time speech recognition, while on-device and offline speech recognition ensure privacy and low-latency operation. For developers looking to build voice-driven applications, integrating a
Voice SDK
can streamline the process of adding real-time audio features alongside ASR capabilities.Here's a basic example of making an ASR API call in Python, using a hypothetical cloud-based ASR service:
1import requests
2
3API_KEY = "your_api_key_here"
4audio_file_path = "./audio_sample.wav"
5
6with open(audio_file_path, "rb") as audio_file:
7 files = {"file": audio_file}
8 headers = {"Authorization": f"Bearer {API_KEY}"}
9 response = requests.post(
10 "https://api.exampleasr.com/v1/transcribe",
11 files=files,
12 headers=headers
13 )
14
15if response.ok:
16 print("Transcription:", response.json()["transcript"])
17else:
18 print("Error:", response.text)
19This snippet demonstrates uploading an audio file and retrieving the transcribed text, showcasing how straightforward ASR integration can be in developer workflows. If you're building with Python, consider leveraging a
python video and audio calling sdk
to further enhance your application's communication features.Key Features of Automatic Speech Recognition Software
Real-Time and Batch Transcription
Automatic speech recognition software provides both real-time and batch transcription capabilities. Real-time speech recognition is crucial for live captions, accessibility tools, and interactive applications, providing near-instant feedback. Batch transcription, on the other hand, is ideal for processing large audio archives, such as podcasts, webinars, or YouTube videos, converting hours of content into searchable text efficiently.
For developers working with web technologies, integrating a
javascript video and audio calling sdk
can enable seamless audio and video communication, which pairs well with ASR for live transcription and collaboration.Multi-Language Support and Translation
Modern ASR solutions offer robust multi-language transcription, supporting dozens or even hundreds of languages and dialects. Advanced systems also provide real-time translation, enabling cross-language communication and global content reach. AI-driven ASR adapts to speakers' accents and context, ensuring accurate, context-aware transcription and translation for diverse user bases.
Privacy, Security, and Offline Capabilities
As voice data is inherently sensitive, privacy and security are paramount in ASR deployments. Many platforms offer end-to-end encryption, on-premises deployment, and offline speech recognition to address regulatory requirements and protect confidential information. Offline ASR is particularly valuable in environments where internet access is limited or security policies prohibit cloud services.
When privacy is a concern, some solutions also offer integration with a
Voice SDK
that supports secure, encrypted audio streams, ensuring compliance with strict data protection standards.Exporting, Editing, and Integration Options
ASR software typically supports exporting transcriptions in formats like SRT, VTT, or plain text, streamlining subtitle generation and content repurposing. Integration options via APIs or SDKs enable seamless embedding of ASR into custom workflows, while built-in editors allow users to review and correct transcriptions easily.
For those building conferencing or collaboration tools, a robust
Video Calling API
can be integrated alongside ASR to provide a complete communication solution.Popular Automatic Speech Recognition Software Solutions
Whisper AI and Whisper V3
Whisper AI, developed by OpenAI, is a state-of-the-art open source ASR system renowned for its high accuracy, multi-language support, and robust performance in noisy environments. Whisper V3, its latest iteration in 2025, further enhances transcription accuracy, speaker diarization, and translation features.
Use Cases:
- Real-time and batch transcription for videos, podcasts, and meetings
- YouTube transcription and subtitle generation
- Accessibility solutions for voice typing and content repurposing
Sample: Using Whisper in Python via CLI
1# Install Whisper using pip
2pip install openai-whisper
3
4# Transcribe an audio file to text
5whisper ./audio_sample.mp3 --model medium --language English --output_format srt
6Or programmatically:
1import whisper
2model = whisper.load_model("base")
3result = model.transcribe("audio_sample.mp3")
4print(result["text"])
5Whisper's open architecture enables integration into various platforms, with extensive community support for custom workflows. For developers seeking to add live audio features or voice chat to their applications, a
Voice SDK
can be a valuable complement to ASR for a richer user experience.Speechmaker, Chirp, Cockatoo, and Others
Speechmaker: A cloud-based ASR platform offering high accuracy, speaker diarization, and batch transcription optimized for content creators. It supports SRT export, multi-language transcription, and integrates with YouTube and other content platforms.
Chirp: Focused on real-time speech recognition, Chirp delivers ultra-low latency transcription for live events, webinars, and accessibility tools. Its robust API and browser-based implementation make it ideal for developers building interactive voice applications.
Cockatoo: Cockatoo is tailored for privacy-sensitive environments, providing on-premises and offline speech recognition. Its advanced security features make it suitable for legal, healthcare, and enterprise settings requiring strict compliance.
Speechlogger and VoiceNotebook: These browser-based solutions excel in quick voice typing, note-taking, and transcription for individual users, emphasizing ease of use and accessibility.
If your use case involves telephony or integrating voice features into phone systems, exploring a
phone call api
can help bridge the gap between traditional calls and modern ASR-powered applications.| Solution | Strengths | Platforms |
|---|---|---|
| Whisper AI | Open source, accuracy, language support | Desktop, cloud, CLI |
| Speechmaker | Batch, content repurposing, SRT export | Cloud, web |
| Chirp | Real-time, low-latency, developer API | Web, API, browser |
| Cockatoo | Privacy, offline, on-premises | Desktop, enterprise |
| Speechlogger | Accessibility, browser integration | Web, Chrome extension |
| VoiceNotebook | Voice typing, simplicity | Web, desktop |
Open Source vs. Proprietary Solutions
Open source ASR, such as Whisper AI, offers transparency, community-driven improvements, and lower costs. Developers can customize models for specific domains or integrate them without licensing restrictions. Proprietary solutions, while often providing higher support levels and managed infrastructure, may involve recurring fees and limited customization. The choice depends on required control, budget, and compliance needs.
Implementation: How to Integrate and Use ASR in Your Workflow
ASR integration can follow several approaches:
- Desktop solutions like Whisper or Cockatoo allow offline batch processing and enhanced privacy.
- Cloud-based ASR (e.g., Speechmaker, Chirp) offers scalability and easy API access for real-time and large-scale processing.
- Browser-based tools (e.g., Speechlogger, VoiceNotebook) enable voice typing and quick transcriptions without installation.
For teams building communication platforms, integrating a
Video Calling API
can provide a foundation for audio and video interactions, which can then be enhanced with ASR for transcription and accessibility.API Integration Example:
1import requests
2
3def transcribe_audio(audio_path):
4 with open(audio_path, "rb") as f:
5 response = requests.post(
6 "https://api.speechmaker.com/v1/transcribe",
7 headers={"Authorization": "Bearer YOUR_TOKEN"},
8 files={"audio": f}
9 )
10 return response.json()["transcript"]
11
12print(transcribe_audio("meeting.wav"))
13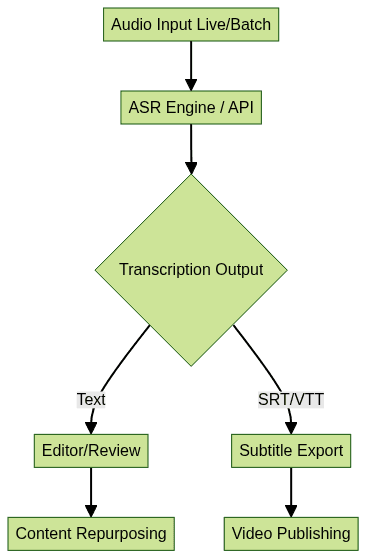
This diagram outlines a typical ASR workflow, from audio ingestion through transcription, editing, and final export for distribution or further processing. If you're interested in adding live audio rooms or group voice chat to your workflow, a
Voice SDK
can be seamlessly integrated with ASR for collaborative experiences.Key Considerations When Choosing Automatic Speech Recognition Software
When selecting ASR software, consider these critical factors:
- Accuracy: Evaluate real-world performance, especially with diverse accents and noisy environments.
- Pricing: Assess cost structures—per minute, per user, or flat fee—and check for hidden fees on exports or integrations.
- Speed: Ensure the solution meets your latency requirements for real-time or batch use cases.
- Privacy and Security: Confirm compliance with data protection regulations and availability of offline or on-premises options.
- Compatibility: Look for support for your preferred programming languages, platforms, and integration points (APIs, SDKs, or browser extensions).
For those seeking to experiment with ASR and communication APIs, you can
Try it for free
to evaluate features and integration options before committing to a solution.Future of Automatic Speech Recognition Software
By 2025, automatic speech recognition software is set to become even more intelligent, context-aware, and accessible. Expect advancements in speaker diarization, real-time translation, and seamless integration with AR/VR and IoT devices. Open source ASR models will continue to close the gap with proprietary offerings, driving innovation and democratizing access to high-quality voice recognition.
Conclusion
Automatic speech recognition software is transforming how we interact with technology. Explore the diverse ASR tools and integration strategies to enhance your workflows, improve accessibility, and unlock new possibilities in 2025.
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ