Introduction
A voice-controlled assistant with Google LLM leverages the power of large language models (LLMs) and advanced voice recognition to deliver hands-free, AI-powered support in daily life. At the forefront of this field is Gemini, Google’s next-generation conversational AI platform that brings deep natural language processing (NLP), multi-modal interaction, and seamless integration with the Google ecosystem. As voice-controlled assistants become increasingly central to productivity, accessibility, and smart home automation, understanding the features and technical underpinnings of Google LLM-powered solutions is crucial for developers and users alike. In 2025, the synergy between AI, voice interfaces, and cloud capabilities is reshaping how we interact with information and devices, setting new standards for convenience, privacy, and personalized experiences.
What is a Voice-Controlled Assistant with Google LLM?
A voice-controlled assistant with Google LLM is an AI-powered software agent that interprets spoken instructions, processes them using Google’s large language models, and executes tasks or provides information accordingly. Unlike traditional voice assistants, these systems leverage the latest advancements in NLP and natural language understanding (NLU) to interpret, reason, and respond to complex queries with context and nuance.
Central technologies include:
- Natural Language Processing (NLP): Enables the assistant to understand intent, sentiment, and context in user commands.
- Natural Language Understanding (NLU): Dissects meaning and intent for more accurate responses.
- Multi-modal capabilities: Allows the assistant to process not just voice, but also text, images, and contextual data.
For developers looking to build or enhance their own assistants, integrating a
Voice SDK
can streamline the process of capturing and processing high-quality audio input, ensuring seamless communication between users and AI systems.Gemini exemplifies this next-generation approach, combining state-of-the-art LLMs with robust voice recognition and contextual awareness. By harnessing these tools, Gemini offers more natural conversations, deeper Google app integration, and proactive assistance for a wide range of tasks—from managing emails to controlling smart home devices.
Key Features of Gemini: Google’s Voice-Controlled Assistant
Gemini sets itself apart in the landscape of voice-controlled assistants with Google LLM by introducing several groundbreaking features:
Natural Language Understanding and Conversational AI
Gemini’s core strength lies in its conversational AI, powered by the latest large language models. This enables:
- Contextual Awareness: Recognizing previous interactions and ongoing context.
- Natural Conversation: Handling follow-up questions, ambiguity, and multi-turn dialogues.
- Dynamic Adaptation: Adjusting tone, style, and information based on user preferences.
For applications that require real-time communication, integrating a
Video Calling API
can further enhance the assistant’s capabilities, enabling seamless transitions between voice commands and live video interactions.Hands-Free Help and Smart Home Integration
With advanced voice recognition, Gemini provides truly hands-free interaction. It seamlessly controls smart home devices (lights, thermostats, security systems), launches routines, and manages appliances—making it ideal for accessibility and convenience.
Developers aiming for cross-platform compatibility can leverage solutions like the
android video and audio calling sdk
to enable robust voice and video features on Android devices, ensuring a consistent user experience across smartphones and tablets.Contextual Awareness and Personalized Assistance
Gemini’s large language model enables it to remember context across sessions, deliver personalized recommendations, and automate recurring tasks. For example, it can suggest optimal travel routes based on your calendar, or remind you of meetings tailored to your time zone.
If you’re building assistants that require embedded communication features, consider using an
embed video calling sdk
to quickly add video and audio calling capabilities to your app without extensive custom development.Integration with Google Apps
Deep integration with Gmail, Calendar, Maps, and more allows Gemini to:
- Read and draft emails
- Schedule appointments
- Provide direction and traffic updates
- Automate repetitive tasks across the Google ecosystem
For those seeking to enable phone-based interactions, integrating a
phone call api
can empower your assistant to make and receive calls, expanding its utility beyond traditional app environments.Comparing Gemini with Traditional Google Assistant

How Does a Voice-Controlled Assistant with Google LLM Work?
The technical workflow of a voice-controlled assistant with Google LLM involves multiple stages:
- Voice Input: The user issues a spoken command via a microphone-enabled device.
- Speech Recognition: Audio is transcribed to text using Google’s speech-to-text API.
- Natural Language Processing: The transcribed text is analyzed by Gemini’s LLM to extract intent, context, and required actions.
- Execution/Integration: The assistant triggers appropriate actions (e.g., querying Gmail, controlling smart devices).
- Response Generation: Gemini crafts a natural, context-aware reply, delivered via voice or text.
For developers working with Python, the
python video and audio calling sdk
offers a straightforward way to add real-time audio and video communication to your assistant, making it possible to support interactive features like live help or remote collaboration.Workflow Diagram
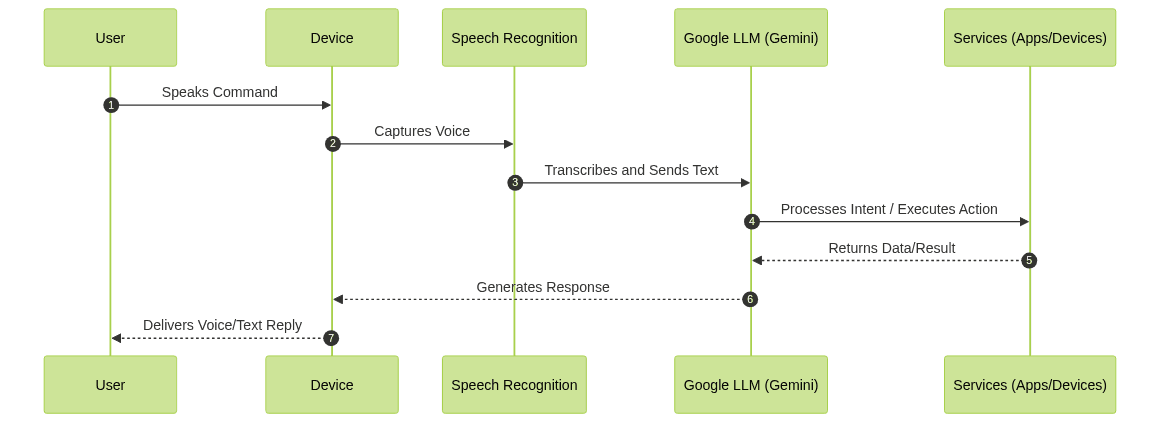
Example API Call to Google Gemini/LLM for Voice Input
Below is a sample Python snippet demonstrating how to send transcribed voice input to the Gemini API:
1import requests
2
3API_URL = "https://api.gemini.google.com/v1/assist"
4API_KEY = "YOUR_API_KEY" # Replace with your actual API key
5
6headers = {
7 "Authorization": f"Bearer {API_KEY}",
8 "Content-Type": "application/json"
9}
10
11def send_voice_command(transcribed_text):
12 payload = {
13 "query": transcribed_text,
14 "context": {
15 "user": "user_id_1234",
16 "device": "smart_speaker"
17 }
18 }
19 response = requests.post(API_URL, headers=headers, json=payload)
20 return response.json()
21
22# Example usage
23result = send_voice_command("What\'s on my calendar for today?")
24print(result)
25If you’re developing web-based assistants, the
javascript video and audio calling sdk
provides a flexible toolkit for integrating real-time communication directly into your browser applications.Implementation Guide: Building Your Own Voice-Controlled Assistant
Building a custom voice-controlled assistant with Google LLM in 2025 involves several steps:
Prerequisites
- Google Cloud Account with access to Gemini or the latest LLM APIs
- API Credentials (OAuth2 tokens, API keys)
- Microphone-enabled device (Raspberry Pi, smart speaker, smartphone)
- Google Cloud SDKs for Python or Node.js
For advanced voice interaction capabilities, integrating a
Voice SDK
can help you deliver high-quality, low-latency audio experiences essential for responsive assistants.Step-by-Step Implementation
1. Capture Voice Input
Using Python (with
speech_recognition):1import speech_recognition as sr
2
3recognizer = sr.Recognizer()
4with sr.Microphone() as source:
5 print("Listening...")
6 audio = recognizer.listen(source)
7 try:
8 user_text = recognizer.recognize_google(audio)
9 print(f"User said: {user_text}")
10 except sr.UnknownValueError:
11 print("Could not understand audio")
122. Send to Google LLM
Refer to the API call example above. For Node.js:
1const axios = require("axios");
2
3const API_URL = "https://api.gemini.google.com/v1/assist";
4const API_KEY = "YOUR_API_KEY"; // Replace with your actual API key
5
6async function sendVoiceCommand(transcribedText) {
7 const response = await axios.post(
8 API_URL,
9 {
10 query: transcribedText,
11 context: {
12 user: "user_id_1234",
13 device: "smart_speaker"
14 }
15 },
16 {
17 headers: {
18 Authorization: `Bearer ${API_KEY}`,
19 "Content-Type": "application/json"
20 }
21 }
22 );
23 return response.data;
24}
25
26// Example usage
27sendVoiceCommand("Turn on the living room lights.")
28 .then(result => console.log(result));
293. Handle Output and Multi-Turn Conversations
Gemini supports context management for multi-turn dialogues. Store conversation context (session tokens or previous queries) and include it in subsequent API calls for seamless interactions.
4. Integrate with Smart Home and Google Apps
Use Google APIs (e.g., HomeGraph, Gmail, Calendar) to execute actions received from Gemini’s LLM. Example integration:
1# Pseudo-code for handling smart device commands
2if "turn on" in result["intent"] and "lights" in result["entities"]:
3 trigger_smart_home_action("lights", "on")
4For group audio experiences or collaborative environments, a
Voice SDK
can be invaluable for managing live audio rooms and facilitating real-time discussions.Best Practices
- Handle errors gracefully (e.g., unclear speech or ambiguous intent)
- Respect user privacy—never store audio/transcripts longer than necessary
- Ensure secure storage of API keys and sensitive data
Privacy, Security, and User Control
Google’s Gemini platform is built with privacy and user control as core principles. All voice data is encrypted in transit and at rest. Users are provided with granular controls to review, manage, or delete their voice interactions and data stored within the Google ecosystem. Transparency tools allow users to see what data is collected and how it is used, with opt-in/opt-out options for personalization features.
Developers should implement robust security practices, including:
- Using OAuth2 for authentication
- Regularly rotating API keys
- Minimizing data retention and anonymizing usage logs
In 2025, user trust is central—ensuring privacy, transparency, and data sovereignty must be a top priority for any AI-powered assistant.
Practical Use Cases and Future Potential
Voice-controlled assistants with Google LLM are revolutionizing:
- Smart Home Automation: Control lights, appliances, routines, and security systems via voice.
- Productivity and Research: Draft emails, summarize documents, manage calendars, and fetch real-time information hands-free.
- Accessibility and Inclusion: Enable users with limited mobility or visual impairments to interact with technology seamlessly.
- Future Trends: Expect more proactive, multi-modal AI that combines voice, vision, and context to anticipate user needs and perform complex tasks.
For teams looking to experiment with these technologies, you can
Try it for free
and start building your own voice-controlled solutions today.As Gemini and Google’s LLMs evolve, next-gen assistants will become even more context-aware, proactive, and integral to daily workflows.
Conclusion
A voice-controlled assistant with Google LLM like Gemini delivers unparalleled convenience, productivity, and personalized help in 2025. By combining advanced NLP, contextual awareness, and seamless Google integration, Gemini redefines what’s possible with conversational AI. Now is the perfect time for developers and users to explore building and leveraging these next-generation assistants for smarter, more efficient living.
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ