Introduction to Real-Time LLM Conversation
The landscape of artificial intelligence is rapidly evolving, and nowhere is this more evident than in the emergence of real-time LLM conversation. Real-time LLM conversation refers to seamless, interactive exchanges between humans and large language models (LLMs), where responses are delivered instantly as users type. This technology is the backbone of modern conversational AI, enabling applications that demand immediate feedback, intuitive context switching, and dynamic human-AI collaboration. As we move through 2025, the importance of real-time LLM conversation grows across industries, powering chatbots, virtual assistants, creative tools, and customer support systems. In this guide, we explore the key technologies, implementation steps, and best practices for building and optimizing real-time LLM conversations.
What is a Real-Time LLM Conversation?
Large Language Models (LLMs) are neural language models trained on enormous datasets to understand and generate human-like text. Conversational AI leverages LLMs to enable natural, context-aware dialogues between humans and machines. A real-time LLM conversation differs from traditional batch-processing models in its ability to stream responses as soon as they are generated, rather than waiting for the entire message to be composed. This eliminates frustrating latency, fosters more engaging interactions, and supports advanced use cases like live translation and real-time collaboration.
The core difference between real-time and batch LLM conversation lies in data flow and response times. Real-time setups use streaming APIs to deliver partial outputs, while batch systems return full answers only after processing completes. For developers building interactive applications, integrating a
Live Streaming API SDK
can further enhance real-time communication capabilities alongside LLMs.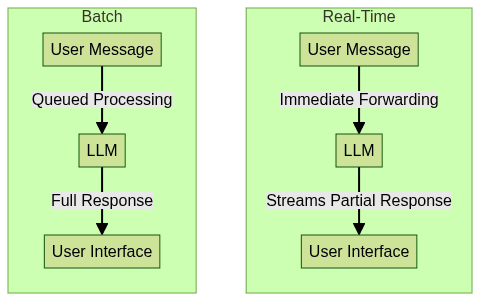
In summary, real-time LLM conversation enhances user experience by streaming LLM responses, supporting natural, fluid exchanges.
Key Technologies Powering Real-Time LLM Conversation
Real-time LLM conversation relies on advanced platforms and APIs optimized for low latency and flexible integration. Here are some of the leading technologies in 2025:
In addition to LLM platforms, integrating communication tools such as a
Video Calling API
or aVoice SDK
can enable seamless video and audio interactions within conversational AI applications.LlamaIndex and Bedrock Converse
LlamaIndex offers an open-source stack for building context-aware LLM applications with streaming and message memory. Bedrock Converse, part of AWS Bedrock, provides scalable, production-ready LLM endpoints with native streaming.
1# Python: Initiate a streaming conversation with LlamaIndex
2from llama_index.llms import StreamingLLM
3llm = StreamingLLM(api_key="YOUR_API_KEY")
4stream = llm.stream("Hello, can you help me?")
5for message in stream:
6 print(message)
7For developers looking to build cross-platform solutions, resources like
flutter webrtc
offer guidance on implementing real-time video and audio features in Flutter apps.Character AI and GPT-6
Character AI allows users to create custom conversational personas, each powered by advanced neural language models. GPT-6, the latest in OpenAI's GPT series, brings improved contextual understanding and ultra-low-latency streaming for real-time chat.
- Character AI: Persona-driven, customizable chatbots with dynamic real-time interaction.
- GPT-6: State-of-the-art contextual recall, message streaming, and human-like conversation.
If you want to quickly add video and audio calling to your web app, consider using a
javascript video and audio calling sdk
for seamless integration.Streaming APIs and Latency Reduction
Streaming APIs are critical for real-time LLM conversation, enabling partial responses and reducing perceived latency. Efficient message streaming improves user engagement and scales across concurrent connections. For Python developers, leveraging a
python video and audio calling sdk
can help integrate real-time communication features alongside LLM-powered chat.1# Streaming LLM responses with a generic API
2import requests
3headers = {"Authorization": "Bearer YOUR_TOKEN"}
4with requests.get("https://api.llmprovider.com/v1/chat/stream", headers=headers, stream=True) as r:
5 for chunk in r.iter_content():
6 print(chunk.decode(), end="")
7How to Implement Real-Time LLM Conversations: Step-by-Step Guide
Building a real-time LLM conversation system involves several technical steps, from selecting a neural language model to integrating streaming APIs and optimizing user experience. If you're looking for a fast deployment, you can
embed video calling sdk
components directly into your application for instant video and audio chat functionality.Step 1: Choosing the Right LLM Platform
Selecting the best LLM platform depends on your use case, scalability needs, and required features. Here's a comparison:
| Platform | Streaming Support | Customization | Scalability | Example Use Case |
|---|---|---|---|---|
| LlamaIndex | Yes | High | Medium | Knowledge-based chatbots |
| Bedrock Converse | Yes | Medium | High | Enterprise virtual agents |
| Character AI | Yes | Very High | Medium | Persona-driven assistants |
| GPT-6 | Yes | Medium | Very High | General conversational AI |
For mobile developers, a
react native video and audio calling sdk
can be integrated to provide real-time communication features within React Native apps.Step 2: Setting Up API Access and Authentication
Most LLM services require secure API authentication. Here's an example using Python:
1import os
2import requests
3api_key = os.environ.get("LLM_API_KEY")
4headers = {"Authorization": f"Bearer {api_key}"}
5# Test authentication
6response = requests.get("https://api.llmprovider.com/v1/me", headers=headers)
7print(response.json())
8Step 3: Sending and Receiving Messages
After authentication, you can send user messages and receive LLM responses. This example illustrates a typical message exchange:
1import requests
2headers = {"Authorization": "Bearer YOUR_API_KEY"}
3data = {"message": "What\'s the weather today?"}
4response = requests.post("https://api.llmprovider.com/v1/chat", headers=headers, json=data)
5print(response.json()["response"])
6Step 4: Enabling Streaming Responses
For real-time LLM conversation, implement streaming to handle partial outputs and deliver instant feedback:
1import requests
2headers = {"Authorization": "Bearer YOUR_API_KEY"}
3with requests.get("https://api.llmprovider.com/v1/chat/stream", headers=headers, stream=True) as r:
4 for chunk in r.iter_content():
5 print(chunk.decode(), end="")
6This streaming message loop can be integrated into chat UIs for dynamic conversational AI experiences. To further enhance your application's interactivity, consider leveraging a
Live Streaming API SDK
for scalable, real-time video and audio streaming.Best Practices for Real-Time LLM Conversations
Prompt Engineering for Contextual Understanding
Effective prompt engineering is key for contextual understanding in real-time LLM conversation. Design prompts that inject recent context and clarify user intent:
1prompt = (
2 "You are an AI assistant. The user previously asked about cloud costs. "
3 "Continue the conversation about AWS pricing tiers."
4)
5- Use explicit context summaries
- Guide the LLM toward expected output formats
- Chain prompts for multi-turn memory
Managing Latency and Scaling
To minimize latency and ensure scalability:
- Use platforms with native streaming and low-latency endpoints
- Deploy close to users for lower network round-trip times
- Implement asynchronous message handling
- Scale horizontally with stateless microservices
User Experience Considerations
Provide real-time feedback (typing indicators, streamed text), robust error handling, and graceful fallbacks in case of LLM timeouts or failures for seamless user experience.
Use Cases and Applications
Real-time LLM conversation powers a new generation of interactive applications:
- Customer Support Chatbots: Deliver instant, context-aware answers, escalate to humans as needed
- Creative Collaboration Tools: Assist writers, designers, and engineers with dynamic AI brainstorming
- Educational Platforms: Enable tutors, language learning, and adaptive instruction in real time
- Live Translation and Accessibility: Provide on-demand translation and content adaptation for diverse audiences
These use cases demonstrate how real-time LLM conversation drives productivity, inclusivity, and creativity in 2025. If you're interested in building similar solutions, you can
Try it for free
and experiment with real-time APIs and SDKs.Ethical Considerations and Limitations
While real-time LLM conversation unlocks powerful new capabilities, it also raises important ethical and technical challenges:
- Bias and Fairness: LLMs may reflect or amplify biases in training data; monitoring and correction are required
- Transparency: Users should be aware when interacting with AI, and logs should be maintained for accountability
- Model Limitations: LLMs can hallucinate or misinterpret ambiguous prompts—human-in-the-loop systems can mitigate risk
Responsible deployment means balancing automation with oversight.
Future Trends in Real-Time LLM Conversation
Looking ahead, expect multimodal real-time chat (combining text, voice, and images), even more human-like interaction, and wider adoption of ethical AI standards for trustworthy conversational AI.
Conclusion
Real-time LLM conversation is transforming how we interact with AI in 2025. By leveraging streaming APIs, best practices, and thoughtful design, developers can create fluid, intelligent, and engaging conversational experiences.
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ