Introduction
The advent of multilingual large language models (LLMs) is transforming the landscape of voice agents in 2025. These sophisticated AI systems enable seamless communication across languages, breaking down barriers for global businesses and users. As demand for real-time, natural voice interaction rises, the need for multilingual LLMs in voice agents becomes critical. From customer service bots to healthcare assistants, the integration of advanced speech-to-speech translation, language identification, and persona-aware voice synthesis is redefining what’s possible in conversational AI. This post unpacks the core technologies, implementation steps, and future trends of multilingual LLMs for voice agents.
What is a Multilingual LLM for Voice Agents?
A multilingual LLM for voice agents is an AI-powered model designed to understand, process, and generate speech in multiple languages. Unlike traditional voice agents limited to single languages or static rule-based translation, multilingual LLMs leverage deep learning to handle real-time multilingual interactions, including code-switching and context retention. Core components include automatic speech recognition (ASR), text-to-speech (TTS), speech-to-speech translation (S2ST), and language identification. These models go beyond basic translation by enabling nuanced, context-aware, and persona-driven voice synthesis.
Modern solutions such as PolyVoice, Voila, and SIMA exemplify multilingual LLMs for voice agents, delivering polyglot AI experiences and supporting a growing range of languages. These systems employ LLM-based speech synthesis and audio language modeling to adapt to diverse accents and dialects, ensuring robust customer experiences across markets. Integrating a
Voice SDK
can further streamline the development and deployment of such multilingual voice agents, providing essential tools for real-time audio processing.Key Technologies Behind Multilingual Voice Agents
Speech-to-Speech Translation (S2ST)
At the heart of multilingual LLMs for voice agents is speech-to-speech translation. Traditional S2ST relied on chaining ASR, machine translation, and TTS. Modern approaches utilize large language models to perform direct mapping between speech signals, leveraging unit-based audio language models. Instead of translating text, these models operate on discretized speech units (audio tokens), preserving voice characteristics and prosody. For developers looking to enable real-time voice communication, leveraging a
phone call api
can facilitate seamless integration of these advanced features into their applications.1# Example: Discretizing speech units using k-means clustering
2import numpy as np
3from sklearn.cluster import KMeans
4
5def discretize_speech_features(features, num_clusters=512):
6 kmeans = KMeans(n_clusters=num_clusters)
7 tokens = kmeans.fit_predict(features)
8 return tokens
9This approach enables real-time, high-quality S2ST, a core feature for multilingual voice assistants and LLM-based speech synthesis.
Automatic Speech Recognition (ASR) & Text-to-Speech (TTS)
Multilingual LLMs integrate ASR and TTS pipelines to process and generate speech across languages. ASR converts spoken language into text, while TTS synthesizes natural-sounding speech from generated or translated text. Handling low-resource languages is a key challenge; LLMs can leverage transfer learning and multilingual embeddings to provide support where data is scarce.
A streaming vocoder further enables real-time voice interaction. When building solutions that require both audio and video communication, integrating a
Video Calling API
can provide a unified platform for seamless user experiences.1# Pseudo-code for a streaming vocoder pipeline
2class StreamingVocoder:
3 def __init__(self, model):
4 self.model = model
5 def stream(self, audio_chunk):
6 return self.model.generate(audio_chunk)
7
8vocoder = StreamingVocoder(pretrained_vocoder_model)
9output_audio = vocoder.stream(input_audio_chunk)
10Through these technologies, modern voice agents achieve full-duplex conversation, voice switching, and highly expressive audio output. For developers seeking to
embed video calling sdk
capabilities alongside voice features, prebuilt solutions can accelerate deployment and ensure high-quality interactions.Advantages of Multilingual LLMs for Voice Agents
Multilingual LLMs deliver substantial benefits for voice agent deployment. They enable consistent customer experiences by supporting users in their preferred languages, even in code-switched conversations. Solutions like PolyAI demonstrate rapid language onboarding, with new language support added in weeks rather than months. Persona-aware and emotionally expressive voice generation enhances engagement, tailoring voices for brand consistency and user trust.
From a business perspective, multilingual LLMs offer cost efficiency and scalable architecture. Cloud-based polyglot AI platforms can serve global markets without the need for multiple monolingual systems, reducing infrastructure and maintenance overhead. These benefits drive adoption in customer service, health diagnostics, and beyond. Leveraging a robust
Live Streaming API SDK
can further extend the reach of voice agents, enabling interactive and scalable real-time communication across global audiences.Challenges and Limitations
Despite their promise, multilingual LLMs for voice agents face significant challenges. Expanding language coverage remains difficult, especially for low-resource languages with limited training data. Data imbalance can introduce model bias, impacting translation quality and voice characteristics. Real-time interaction demands low-latency pipelines—balancing speed and accuracy is an ongoing technical challenge. Additionally, safety-aware evaluation and ethical considerations, such as preventing misuse or bias amplification, are critical for responsible deployment.
Implementation: Building a Multilingual LLM Voice Agent
Step-by-Step Workflow
- Data Collection & Preprocessing: Gather multilingual speech datasets, ensuring coverage of target languages and accents. Preprocess audio for noise reduction and normalization.
- Model Selection: Choose a base multilingual LLM (e.g., wav2vec, Whisper, or custom SLLM) that supports ASR, TTS, and S2ST. Developers working with Python can benefit from a
python video and audio calling sdk
to rapidly prototype and integrate communication features.
1# Example: Loading a multilingual LLM with HuggingFace Transformers
2from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
3
4tokenizer = AutoTokenizer.from_pretrained("facebook/mms-tts")
5model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mms-tts")
6- Training and Fine-Tuning: Fine-tune the model on in-domain, multilingual datasets. Use transfer learning for low-resource languages, and augment data with synthetic samples if needed.
- Evaluation: Assess model performance using benchmarks like mSTEB, focusing on translation quality, voice characteristics, and context retention.
Language Identification and Switching
Robust language identification is essential for seamless code-switching and context retention. The workflow typically involves integrating a
Voice SDK
to manage real-time audio streams and facilitate smooth transitions between languages.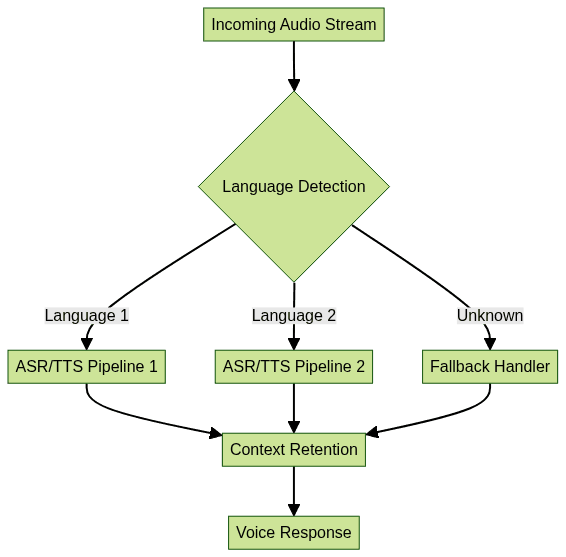
During conversation, context-aware switching allows the agent to maintain topic continuity, even as speakers change languages mid-sentence. Handling code-switching requires the model to dynamically route audio segments to the correct pipeline without losing conversational context.
Customizing Voice Output
Defining a distinctive voice persona is vital for brand consistency. LLMs can be conditioned on speaker embeddings or style tokens to synthesize specific personas, accents, or emotional tones. Audio token prediction enables streaming, low-latency output for real-time applications. Utilizing a
Voice SDK
can help brands maintain consistent voice output across platforms and languages.For example, a brand can deploy a consistent voice across languages:
1# Define a voice persona using speaker embeddings
2persona_embedding = get_speaker_embedding("BrandVoice2025")
3voice_output = model.generate(input_text, speaker_embedding=persona_embedding)
4This ensures every interaction reflects the desired brand identity, enhancing customer trust and engagement.
Case Studies and Real-World Applications
- PolyAI: Powers customer service voice agents with multilingual LLMs, supporting rapid onboarding for new languages and delivering context-aware, persona-driven conversations.
- Voila: Implements real-time autonomous interaction with streaming S2ST and robust language identification for global users.
- VocalAgent: Uses multilingual voice agents in healthcare, supporting diagnostics and guidance across diverse patient populations.
These examples illustrate the versatility and impact of multilingual LLMs for voice agents in mission-critical domains. For organizations seeking to build similar solutions, integrating a
Voice SDK
can provide the foundational technology needed for scalable, real-time voice communication.Future Trends in Multilingual LLMs for Voice Agents
Looking ahead to 2025, advances in model architectures—such as larger, more efficient SLLMs—will improve translation quality, streaming, and support for low-resource languages. Expanding into new domains like education, entertainment, and smart devices will drive further innovation. As safety-aware evaluation and ethical frameworks mature, multilingual LLMs for voice agents will become indispensable tools for global communication.
Conclusion
Multilingual LLMs for voice agents are revolutionizing conversational AI, enabling scalable, nuanced, and context-aware multilingual voice interaction. By leveraging advanced speech-to-speech translation, language identification, and persona-driven synthesis, developers can build voice agents that deliver exceptional user experiences in 2025 and beyond. Now is the time to explore and implement multilingual LLMs for your next-generation voice solutions.
Try it for free
and experience the future of multilingual voice technology.Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ