Introduction to LLM for Voice Assistant
A Large Language Model (LLM) for voice assistant is a specialized AI model engineered to comprehend, process, and generate human language through spoken interactions. In 2025, advances in large language models, including DiVA Llama 3 and multimodal LLMs, are redefining how voice AI can understand context, emotion, and intent. These robust LLMs for voice assistants are central to building natural conversational flow, delivering low-latency responses, and enabling privacy-first solutions. As the voice AI landscape evolves, open-source LLM voice assistants are setting new standards for speech recognition, emotional intelligence, and contextual memory, driving the next generation of conversational AI.
How LLMs Power Voice Assistants
What is a Large Language Model?
A Large Language Model (LLM) is an AI system trained on vast datasets of text (and now, speech and multimodal data) to predict, generate, and understand language. LLMs, such as GPT or Llama, learn patterns, context, and semantics, allowing them to power a spectrum of applications—from chatbots to advanced voice assistants capable of nuanced, human-like communication. For developers looking to integrate real-time voice features, leveraging a
Voice SDK
can accelerate the process of building interactive voice-enabled applications.From Text-Only to Multimodal: The Shift to Speech LLMs
Traditional LLMs focused solely on text, but 2025 brings a new generation of multimodal LLMs for voice assistants. These models process not only text but also audio inputs, integrating ASR (automatic speech recognition) with natural language understanding and even emotion detection. This cross-modal fusion enables end-to-end voice assistant systems that deliver seamless, context-aware, and emotionally intelligent interactions. Integrating a
phone call api
can further extend these capabilities, allowing voice assistants to initiate or manage calls as part of their conversational workflows.Key Components of a Voice Assistant LLM Architecture
A modern LLM for voice assistant encompasses several core modules: ASR for converting speech to text, the LLM for understanding and generating responses, speech synthesis (TTS), and context memory. The architecture below illustrates these components. For those building cross-platform solutions, exploring a
python video and audio calling sdk
can streamline the integration of both video and audio features into your voice assistant pipeline.
Core Methods: Distillation, Fine-Tuning, and Training Data
Cross-Modal Context Distillation Explained
Context distillation is a process where knowledge from a larger, often multimodal model is transferred into a smaller, efficient LLM for voice assistant. By aligning representations from speech and text, context distillation enables the model to better understand spoken intent, tone, and context. This process makes voice AI more robust, especially in real-world, noisy environments where context can be lost. Developers can enhance these capabilities by integrating a
javascript video and audio calling sdk
for seamless browser-based voice and video interactions.Fine-Tuning Speech LLMs with ASR Data
Fine-tuning is critical for adapting a general-purpose LLM to a voice assistant domain. By leveraging ASR (automatic speech recognition) datasets — including diverse accents, noisy backgrounds, and conversational audio — developers can fine-tune speech LLMs for higher accuracy and lower latency. This results in a more reliable and responsive end-to-end voice assistant. Utilizing a
react native video and audio calling sdk
can further empower mobile voice assistant applications with robust real-time communication features.Efficient Training Techniques
Modern LLMs for voice assistants utilize techniques such as data augmentation, transfer learning, and quantization. These methods reduce training time and memory footprint, enabling deployment on edge devices and privacy-first local environments. For Android developers, an
android video and audio calling sdk
offers a straightforward way to add high-quality voice and video features to their voice assistant apps.Notable Open-Source LLM Voice Assistants
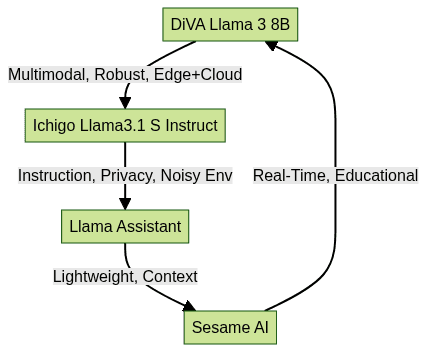
DiVA Llama 3 8B
DiVA Llama 3 8B is an advanced open-source LLM for voice assistant, optimized for multimodal understanding and low-latency response. It incorporates context distillation and fine-tuning for speech-to-text and emotional intelligence tasks. Its architecture supports robust deployment in both cloud and edge settings, making it highly flexible for voice AI development. For those seeking to implement advanced conversational features, a
Voice SDK
can provide scalable infrastructure for live audio interactions.Ichigo Llama3.1 S Instruct
Ichigo Llama3.1 S Instruct is a speech-focused LLM designed for instruction-following and voice presence. It offers strong performance in noisy environments and supports privacy-first deployment, catering to developers seeking control and customization in voice assistant projects. Leveraging a
Voice SDK
can further enhance the real-time capabilities of these open-source models.Llama Assistant and Sesame AI
Llama Assistant and Sesame AI are lightweight, open-source LLM voice assistants. They emphasize efficient ASR integration, contextual memory, and support for real-time conversational AI. These solutions are ideal for rapid prototyping and educational purposes. Integrating with a
Voice SDK
can help bring these assistants to production with minimal effort.Comparison Table
Implementation: Building Your Own LLM Voice Assistant
Selecting the Right Model
Choosing an LLM for voice assistant depends on application requirements: DiVA Llama 3 for multimodal capabilities, Ichigo Llama3.1 S for privacy, or lightweight models for edge deployment.
Setting Up the Environment
A typical setup requires Python 3.10+, CUDA-enabled GPU (for faster inference), and libraries such as transformers, torchaudio, and an ASR backend (e.g., Whisper or Vosk).
Example: Using DiVA Llama 3 for Speech Input
Below is a Python code snippet demonstrating how to use DiVA Llama 3 for a basic voice assistant pipeline:
1import torch
2from transformers import AutoModelForCausalLM, AutoTokenizer
3from transformers import pipeline
4import sounddevice as sd
5import numpy as np
6import whisper
7
8# Load ASR (speech-to-text)
9asr_model = whisper.load_model(\"base\")
10
11def record_audio(duration=5, fs=16000):
12 print(\"Speak now...\")
13 audio = sd.rec(int(duration * fs), samplerate=fs, channels=1)
14 sd.wait()
15 return np.squeeze(audio)
16
17def transcribe(audio, fs=16000):
18 result = asr_model.transcribe(audio, fp16=False)
19 return result[\"text\"]
20
21# Load DiVA Llama 3
22llm = AutoModelForCausalLM.from_pretrained(\"diva-llama-3-8b\")
23tokenizer = AutoTokenizer.from_pretrained(\"diva-llama-3-8b\")
24
25# Voice assistant loop
26audio = record_audio()
27text = transcribe(audio)
28inputs = tokenizer(text, return_tensors=\"pt\")
29output = llm.generate(**inputs, max_length=50)
30response = tokenizer.decode(output[0], skip_special_tokens=True)
31print(\"Assistant:\", response)
32Integrating Speech Recognition and Synthesis
To enable full-duplex voice interaction, integrate speech synthesis (TTS) after generating a response. Example with pyttsx3:
1import pyttsx3
2
3def speak(text):
4 engine = pyttsx3.init()
5 engine.say(text)
6 engine.runAndWait()
7
8speak(response)
9Privacy and Local Deployment Options
Deploying an LLM for voice assistant locally ensures privacy-first operation, avoiding sensitive data transmission. Lightweight models and quantized LLMs can run efficiently on consumer hardware. For those who want to experiment with live audio features, trying a
Voice SDK
can be a valuable addition to your local deployment.Handling Noisy Environments and Robustness
Robust LLM voice assistants leverage noise-robust ASR models and post-processing filters. Techniques like context distillation improve accuracy even with background noise, making the system reliable in real-world scenarios.
Advanced Features: Emotional Intelligence and Contextual Memory
Emotional Intelligence in LLM Voice Assistants
Modern LLMs for voice assistants incorporate emotion recognition modules that analyze tone, prosody, and sentiment. This enables dynamic adjustment of responses, fostering empathetic and engaging conversations. Emotional intelligence is crucial for applications in mental health, customer service, and social robotics.
Contextual Memory and Multi-turn Conversation
LLMs with contextual memory can track and reference previous dialogue turns, maintaining coherent and context-aware interactions. This multi-turn memory is essential for natural conversational flow and allows voice AI to handle complex tasks and user preferences over time.
Evaluation and Benchmarking Voice Assistant LLMs
Key Metrics: Speed, Accuracy, and Latency
Evaluating an LLM for voice assistant involves measuring ASR word error rate (WER), LLM response accuracy, and system latency. Low-latency LLM responses are vital for real-time interaction, while accuracy ensures reliable understanding and intent detection.
Performance on Spoken QA and Real-World Tasks
Voice assistant LLMs are benchmarked on spoken question answering (QA) datasets and real-world task completion. Robustness in noisy environments, handling mixed-language input, and maintaining consistent voice presence are critical for practical deployment.
Limitations and Future Directions
Current Challenges
Despite progress, LLMs for voice assistants face issues with ambiguous speech, context loss, and high computational requirements for real-time inference. Privacy concerns remain for cloud-based solutions.
Future Opportunities
Emerging research in multimodal LLMs, edge AI, continuous learning, and federated fine-tuning will further enhance voice assistant intelligence, privacy, and responsiveness. Developers are encouraged to contribute to open-source projects and push the boundaries of conversational AI.
Conclusion: The Future of LLMs for Voice Assistants
LLMs for voice assistants in 2025 are powering a new era of conversational AI—enabling seamless, robust, and emotionally intelligent voice interfaces. As open-source models and advanced architectures evolve, developers have unprecedented opportunities to innovate, deploy, and personalize voice AI for the future. Get started today by exploring open-source LLMs and building your own next-gen voice assistant!
Try it for free
and experience the possibilities of modern voice technology.Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ