Introduction to Building AI Voice Agents with LLM
In 2025, the fusion of artificial intelligence and voice technology has revolutionized the way we interact with machines. Building an AI voice agent with LLM (large language model) enables developers to craft intelligent assistants capable of understanding and responding to natural speech. An AI voice agent is a software system that processes spoken language and generates meaningful, human-like responses using advanced AI models. LLMs, such as GPT-4 or DeepSeek, are the engines powering these conversational experiences, understanding context, intent, and nuance beyond simple keyword matching.
Over the past decade, voice agents have evolved from simple command-driven bots to sophisticated conversational AI assistants, thanks to breakthroughs in deep learning, speech-to-text, and text-to-speech technologies. Today, AI voice agents are deployed in customer support, healthcare, smart home devices, and more, making seamless, hands-free interactions possible. In this guide, you'll learn how to build an AI voice agent with LLM, explore its architecture, Python implementation, and best practices for real-world deployment in 2025.
Understanding the Core Components of an AI Voice Agent with LLM
The Role of Large Language Models (LLMs)
Large language models (LLMs) are at the core of modern conversational AI. These models, trained on vast corpora of text, excel at understanding, generating, and contextualizing natural language. When you build an AI voice agent with LLM, the LLM acts as the brain, interpreting user intent and generating contextually accurate responses. LLMs like OpenAI's GPT series, DeepSeek, and local open-source models (Llama, Vicuna) are commonly used in production systems.
By leveraging LLMs, AI voice agents provide:
- Dynamic, human-like conversation
- Context awareness and memory
- Multi-turn dialogue management
- Adaptability to various domains
Speech-to-Text and Text-to-Speech Technologies
To enable voice interaction, two key technologies are required:
Speech-to-Text (STT): Converts spoken audio into written text. Popular APIs and libraries include Whisper (open source), AssemblyAI, Azure Speech, and Google Speech-to-Text. These tools provide real-time transcription with high accuracy, even in noisy environments.
Text-to-Speech (TTS): Converts generated text back into natural-sounding speech. Solutions like ElevenLabs, Bark, and open-source engines like pyttsx3 excel at producing lifelike voice synthesis, including support for multiple languages and voices.
Combining LLMs with robust STT and TTS pipelines is essential to build an AI voice agent with LLM that feels natural and responsive. For developers looking to streamline audio interactions, integrating a
Voice SDK
can significantly simplify real-time audio processing and management.Architectures for Building AI Voice Agents
When you build an AI voice agent with LLM, architectural choices impact latency, scalability, and user experience.
Cascading Pipeline vs. Real-Time Models
A common architecture is the cascading pipeline:
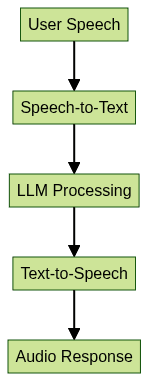
- Chained Approach: Speech is transcribed to text, processed by the LLM, and converted back to audio. This modular approach allows optimizing each component individually.
- Speech-Native Models: Emerging models process audio end-to-end, directly mapping input audio to output speech or intent, reducing latency but requiring more specialized training and hardware.
For projects requiring seamless integration of voice features, using a
Voice SDK
is a practical way to add live audio room capabilities and manage audio streams efficiently.Multi-Agent and Modular Architectures
Modern systems benefit from modularity and flexibility, using frameworks like LangChain, LangGraph, and AutoGen. These tools enable developers to compose complex, multi-agent systems where specialized agents handle tasks such as information retrieval, summarization, or context management.
Key benefits:
- Scalability: Add or swap components (e.g., upgrade LLM or TTS engine) without rewriting the entire pipeline.
- Reusability: Share modules across projects and teams.
- Extensibility: Integrate with APIs, databases, or external knowledge sources.
If your application needs to support both audio and video communication, consider leveraging a
python video and audio calling sdk
for rapid development and robust cross-platform support.Step-by-Step Guide: How to Build an AI Voice Agent with LLM
Let's walk through the process to build an AI voice agent with LLM using Python and state-of-the-art APIs.
Prerequisites and Tools
Before you start, gather the following:
- Python 3.9+ and
Conda
for environment management - API keys for AssemblyAI (STT), ElevenLabs (TTS), OpenAI or DeepSeek (LLM), or set up a local LLM with llama-cpp-python
- Python packages: requests, openai, elevenlabs, assemblyai, pyaudio, sounddevice, langchain (for modular pipelines)
- Access to a microphone and speaker
If your solution requires phone-based communication, integrating a
phone call api
can enable direct voice interactions over traditional telephony networks.Install dependencies:
1conda create -n voice-agent python=3.10
2conda activate voice-agent
3pip install openai elevenlabs assemblyai pyaudio sounddevice langchain
4Setting Up Speech-to-Text
Here's an example using
OpenAI Whisper
for local transcription:1import whisper
2import sounddevice as sd
3import numpy as np
4
5model = whisper.load_model("base")
6duration = 5 # seconds
7fs = 16000
8
9def record_audio():
10 print("Speak now...")
11 audio = sd.rec(int(duration * fs), samplerate=fs, channels=1)
12 sd.wait()
13 return np.squeeze(audio)
14
15# Record and transcribe
16audio_data = record_audio()
17whisper.save_audio("input.wav", audio_data, fs)
18result = model.transcribe("input.wav")
19print("Transcription:", result["text"])
20For cloud STT (AssemblyAI):
1import requests
2
3API_KEY = "your_assemblyai_api_key"
4audio_url = "https://path_to_your_audio.wav"
5
6headers = {"authorization": API_KEY}
7data = {"audio_url": audio_url}
8response = requests.post("https://api.assemblyai.com/v2/transcript", json=data, headers=headers)
9transcript_id = response.json()["id"]
10For developers aiming to embed video calling features alongside voice, an
embed video calling sdk
offers a straightforward way to integrate both audio and video communication into your application.Integrating the LLM
Using OpenAI's GPT-4 API:
1import openai
2
3openai.api_key = "your_openai_api_key"
4
5def query_llm(prompt):
6 response = openai.ChatCompletion.create(
7 model="gpt-4",
8 messages=[{"role": "user", "content": prompt}]
9 )
10 return response["choices"][0]["message"]["content"]
11
12llm_output = query_llm("What\'s the weather like today?")
13print("LLM Response:", llm_output)
14For local LLMs (llama-cpp-python):
1from llama_cpp import Llama
2
3llm = Llama(model_path="./llama-2-7b-chat.ggmlv3.q4_0.bin")
4output = llm("What\'s the weather like today?")
5print("LLM Response:", output)
6If your use case involves more advanced conferencing needs, a robust
Video Calling API
can help facilitate seamless audio and video interactions for your AI agent.Generating Voice Responses
Using ElevenLabs for TTS:
1from elevenlabs import generate, play, set_api_key
2
3set_api_key("your_elevenlabs_api_key")
4
5def speak(text):
6 audio = generate(text=text, voice="Rachel")
7 play(audio)
8
9speak("Hello! How can I assist you today?")
10Open-source TTS with pyttsx3:
1import pyttsx3
2engine = pyttsx3.init()
3engine.say("Hello! How can I assist you today?")
4engine.runAndWait()
5To further enhance your application's real-time audio features, integrating a
Voice SDK
can provide scalable, low-latency audio streaming and management.Putting It All Together: The Voice Agent Loop
The following is a simplified main loop to build an AI voice agent with LLM:
1while True:
2 # 1. Record user speech
3 audio_data = record_audio()
4 whisper.save_audio("input.wav", audio_data, fs)
5 # 2. Transcribe speech to text
6 result = model.transcribe("input.wav")
7 user_text = result["text"]
8 print("User:", user_text)
9 # 3. Generate LLM response
10 llm_response = query_llm(user_text)
11 print("Agent:", llm_response)
12 # 4. Synthesize voice output
13 speak(llm_response)
14Error handling and latency management are crucial. Consider:
- Adding try/except around API calls
- Using threading or async for non-blocking audio processing
- Monitoring latency per stage and optimizing model size or API usage
For applications that require handling phone-based conversations, a
phone call api
can be integrated to bridge your AI agent with telephony systems for broader reach.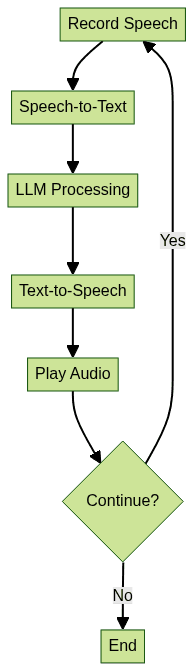
Advanced Techniques: Fine-Tuning and Prompt Engineering
Domain Adaptation (Fine-tuning LLMs)
For specialized applications (e.g., medical, legal, finance), fine-tuning an LLM on domain-specific data improves accuracy and safety. Open-source models (Llama, DeepSeek) can be fine-tuned locally using frameworks like Hugging Face's Transformers.
Example: Fine-tuning a medical assistant LLM on clinical notes for accurate patient conversations.
Prompt Engineering Strategies
Prompt engineering is key when you build an AI voice agent with LLM. Craft prompts with:
- Explicit instructions ("You are a helpful AI medical assistant.")
- Contextual information (previous dialogue turns)
- Constraints ("Answer concisely.")
Experiment, test, and iterate to optimize prompt effectiveness and avoid ambiguous outputs.
Deployment Considerations and Best Practices
When deploying your AI voice agent, consider:
- Cloud vs. Local: Cloud APIs offer scalability but may introduce latency and privacy concerns. Local deployment (on-device LLM, STT, TTS) improves speed and privacy, but may be hardware-limited.
- Privacy: Encrypt user data, avoid unnecessary logging, and comply with local regulations.
- Latency: Optimize pipeline, minimize API calls, and monitor response times.
- User Experience: Provide clear feedback (audio cues), handle errors gracefully, and allow users to interrupt or correct the agent.
For scalable audio experiences, a
Voice SDK
is a valuable tool for managing live audio rooms and ensuring high-quality voice communication.Real-World Use Cases and Industry Applications
AI voice agents built with LLMs are transforming industries in 2025:
- Customer support: Automated, 24/7 voice helplines
- Healthcare: Conversational triage, patient screening
- Personal assistants: Scheduling, reminders, smart home control
- Future trends: Multimodal agents, emotion detection, real-time translation
If you're ready to start building your own AI voice agent or want to experiment with these technologies,
Try it for free
and explore the possibilities for your next project.Conclusion
Building an AI voice agent with LLM in 2025 is more accessible than ever for developers. By combining speech-to-text, large language models, and advanced voice synthesis, you can create powerful, natural, and scalable conversational agents. Experiment with modular architectures, fine-tuning, and prompt engineering to tailor agents for your needs. Start building, iterate fast, and help shape the next generation of AI voice interfaces.
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ