Introduction to AWS Text to Speech
Text to speech technology is transforming how modern applications interact with users by making digital content accessible, engaging, and interactive. With increasing demand for lifelike voice interfaces in 2025, AWS Text to Speech services have become a cornerstone for developers building applications that require speech synthesis, voiceover, or accessibility features. At the forefront of this innovation is Amazon Polly, AWS’s primary text to speech (TTS) engine, empowering cloud TTS solutions with realistic, neural voices and robust integration options.
Understanding AWS Text to Speech: Amazon Polly
Amazon Polly is AWS’s fully managed text to speech service, designed to convert written text into natural-sounding speech. Polly utilizes state-of-the-art deep learning technologies, including neural TTS models, to deliver lifelike voices in multiple languages and dialects. This flexibility enables developers to deliver immersive voice experiences across apps, media content, accessibility tools, and IoT devices. For developers seeking to add real-time voice features to their applications, integrating a
Voice SDK
can further enhance interactivity and engagement.Key Features
- Neural and Standard Voices: Polly offers both traditional concatenative and advanced neural TTS voices for realistic intonation and expressiveness.
- Broad Language Support: Over 60 voices in 30+ languages, with regular additions.
- SSML Support: Fine-grained control over speech output using Speech Synthesis Markup Language.
- Custom Lexicons: Customize pronunciation for technical, branded, or regional terms.
- Streaming & Real-time: Stream audio for low-latency applications.
- Secure & Scalable: Handles millions of requests, compliant with HIPAA and PCI DSS.
Use Cases
- Applications: Speech-enabled apps, interactive bots, and voice assistants. Developers can leverage a
Voice SDK
to build live audio rooms or integrate voice chat into their solutions. - Media: Automated podcasting, video narration, and newsreaders.
- Accessibility: Screen readers, educational tools, and communication aids.
- IoT: Voice announcements for devices, smart home integrations.
AWS Text to Speech Architecture and Components
AWS Text to Speech architecture revolves around Amazon Polly’s API and flexible integration points. Polly receives text input via API requests, processes it using neural voice engines, and returns audio streams or files in formats like MP3, OGG, or PCM. Developers can interact with Polly through the AWS Console, CLI, SDKs, or RESTful API. For those building communication features, exploring a
phone call api
can be a valuable complement to speech synthesis capabilities.Supported Audio Formats
- MP3: Common for apps, web, and mobile.
- OGG: Optimized for streaming and web playback.
- PCM: Raw audio for telephony and embedded systems.
- JSON: For speech marks (timing, word boundaries).
Polly Integration Flow
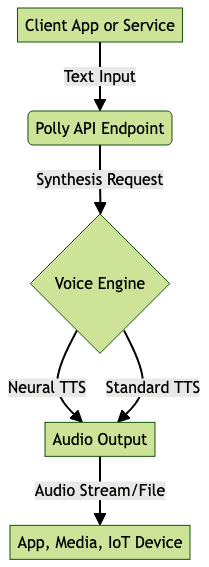
This architecture ensures scalable, secure, and low-latency speech synthesis for a wide variety of applications. If you’re looking to add live voice features, a
Voice SDK
can be integrated alongside Polly to provide interactive audio experiences.Getting Started with AWS Text to Speech
Setting up Your AWS Account
- Register for AWS: Go to the
AWS homepage
and create a free account. - Identity and Access Management (IAM): Set up IAM users/groups with permissions for Amazon Polly ("AmazonPollyFullAccess").
- Access the AWS Console: Sign in to the
AWS Management Console
.
Exploring the Amazon Polly Console
- Navigate to Services > Machine Learning > Amazon Polly.
- The web interface allows you to enter text, select a voice/language, and play or download synthesized speech.
- Adjust speech settings (voice, format, SSML, etc.) using the console’s controls.
First Synthesis Example (Console)
- In the Polly console, enter sample text:
Welcome to AWS Text to Speech powered by Amazon Polly! - Select a neural or standard voice (e.g., "Joanna - Neural").
- Choose output format (e.g., MP3).
- Click Synthesize and listen to/download the audio.
AWS Text to Speech via Amazon Polly’s console is ideal for rapid prototyping and demoing speech output.
Programmatic Access to AWS Text to Speech
Using AWS CLI for Text to Speech
The AWS CLI allows you to synthesize speech directly from your terminal or scripts. Ensure you have the AWS CLI installed and configured with credentials.
1aws polly synthesize-speech \
2 --output-format mp3 \
3 --voice-id "Joanna" \
4 --text "AWS Text to Speech with Amazon Polly in 2025." \
5 output.mp3
6This command will synthesize the specified text into an MP3 file using the "Joanna" voice.
Integrating with AWS SDK in Python
Python developers can use the
boto3 library to interact with the AWS Polly API. If your project also requires real-time communication, consider integrating a python video and audio calling sdk
to enable seamless audio and video interactions:1import boto3
2
3polly = boto3.client("polly")
4response = polly.synthesize_speech(
5 Text="AWS Text to Speech with Amazon Polly in 2025.",
6 OutputFormat="mp3",
7 VoiceId="Joanna"
8)
9
10with open("polly_output.mp3", "wb") as f:
11 f.write(response["AudioStream"].read())
12This code sends a synthesis request and writes the resulting audio stream to an MP3 file.
Other SDKs: JavaScript, Java, iOS, Android
Amazon Polly offers SDKs in multiple languages/platforms:
For developers building cross-platform communication apps, you can also explore the
javascript video and audio calling sdk
,android video and audio calling sdk
, andios video and audio calling sdk
to add robust video and audio features alongside speech synthesis. Additionally, integrating aVoice SDK
can streamline the development of live audio rooms or group calls.These SDKs enable seamless integration of AWS Text to Speech into a wide range of applications.
Customizing Speech Output in AWS Text to Speech
Using SSML for Voice Control
Speech Synthesis Markup Language (SSML) enables developers to control prosody, emphasis, pronunciation, and more. Here’s an SSML example for Polly:
1<speak>
2 Welcome to <emphasis level=\"strong\">AWS Text to Speech</emphasis> with <break time=\"500ms\"/> Amazon Polly.
3</speak>
4To use SSML via the CLI or SDK, set
--text-type ssml or TextType='ssml' respectively.Custom Lexicons
Custom lexicons allow you to define pronunciation for specific words (technical terms, brands, etc.):
- Upload lexicon via the Polly Console or API
- Reference custom lexicon in synthesis requests
Lexicon documentation
Brand Voice and Advanced Features
For organizations needing unique voice identity, Polly offers Brand Voice—custom neural voices trained on proprietary data. This enables businesses to create a distinctive audio brand across touchpoints. Advanced features also include speech marks (timing, phonemes) and real-time streaming APIs.
AWS Text to Speech Best Practices and Security
- Caching & Replay: Cache synthesized audio for frequently requested content to minimize costs and latency.
- Cost Management: Monitor usage, leverage Polly’s free tier for development, and use cost allocation tags for tracking.
- Security: Use IAM policies, VPC endpoints, and encryption to secure TTS data. Polly is compliant with HIPAA, PCI DSS, and other standards.
- Recommended Architectures: Decouple TTS processing (e.g., via S3 and Lambda), and batch process large synthesis jobs for scale.
Pricing, Scalability, and Limitations
AWS Text to Speech pricing is based on the number of characters synthesized. The free tier covers 5 million characters/month for the first 12 months, with pay-as-you-go rates for standard and neural voices. Cost optimization tips:
- Cache and reuse audio
- Batch requests
- Monitor with AWS Budgets
Polly is highly scalable but has limits on request size and throughput. Review
current limits
before integration.Conclusion: The Future of AWS Text to Speech
AWS Text to Speech, powered by Amazon Polly, delivers cutting-edge speech synthesis for developers in 2025. With neural TTS, broad language support, and secure cloud integration, it powers the next generation of speech-enabled applications. As voice AI continues to evolve, expect even richer voices, expanded languages, and innovative brand voice solutions from AWS. If you’re ready to build advanced voice and video applications,
Try it for free
and explore the possibilities of modern communication SDKs.Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ