Introduction to Vosk Speech Recognition
Vosk speech recognition is a powerful, open source toolkit designed for offline, real-time speech-to-text applications. Unlike cloud-based services, Vosk runs entirely on local devices, making it ideal for privacy-focused and bandwidth-limited scenarios. As offline speech recognition gains traction in 2025, Vosk stands out for its developer-friendly APIs, broad language support, and flexible integration options.
For software engineers, IoT developers, and researchers, Vosk speech recognition offers a scalable way to implement voice interfaces, dictation tools, and automated transcription across platforms. With its open source model and active community, Vosk empowers anyone to build robust speech-to-text solutions without relying on proprietary cloud APIs or internet connectivity.
What Makes Vosk Speech Recognition Unique?
Offline Speech Recognition Capability
One of the key features of Vosk speech recognition is its ability to process audio entirely offline. This means speech-to-text can work in environments without internet access, ensuring privacy and low latency, which is critical for edge computing and sensitive applications. For developers seeking to add interactive voice features to their applications, integrating a
Voice SDK
alongside Vosk can further enhance real-time audio experiences.Multilingual Support (20+ Languages)
Vosk speech recognition supports over 20 languages and dialects, including English, Spanish, Chinese, Russian, and more. The open nature of the project allows the community to contribute and expand language models, making Vosk accessible to a diverse global audience.
Lightweight & Portable Models
Vosk's models are optimized for performance and size. Some language models are as small as 50MB, enabling them to run on resource-constrained devices such as Raspberry Pi, smartphones, and embedded systems. If you're building communication tools or integrating with telephony, exploring a
phone call api
can complement Vosk’s offline capabilities for a complete voice solution.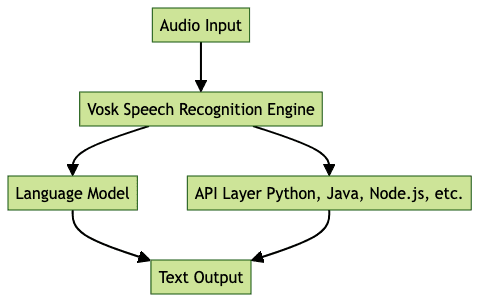
How to Install Vosk Speech Recognition
Python Installation via pip
The quickest way to begin using Vosk speech recognition in Python is via pip:
1pip install vosk
2After installation, you can download pre-trained language models and start transcribing audio within minutes. For those interested in building cross-platform communication tools, consider integrating a
python video and audio calling sdk
to add both video and audio call features to your Python projects.Android Installation (mavenCentral)
For Android, Vosk is available as a library via Maven Central. Add the following dependency to your
build.gradle:1dependencies {
2 implementation 'org.vosk:vosk-android:0.3.40'
3}
4If you’re developing Android apps that require real-time communication, pairing Vosk with a
webrtc android
solution can enable seamless audio and video calling functionalities.Other Platforms (iOS, Raspberry Pi, Windows, Linux, Mac)
Vosk speech recognition provides official support for iOS (via Swift and Objective-C), Raspberry Pi, Windows, Linux, and Mac. Refer to the
Vosk documentation
for platform-specific guides, including C#, JavaScript/Node.js, and Unity integrations. For those working on Android, integrating anandroid video and audio calling sdk
can help you quickly add robust communication features alongside speech recognition.Vosk Speech Recognition API & Integrations
Supported Programming Languages (Python, Java, C#, Node.js, etc.)
Vosk speech recognition offers APIs for Python, Java, C#, Node.js, and more. This multi-language support enables seamless integration with web apps, desktop software, and embedded systems. For web developers, using a
javascript video and audio calling sdk
can complement Vosk’s speech-to-text features with real-time communication capabilities.Streaming API for Real-Time Applications
Vosk features a streaming API for real-time transcription. This is ideal for voice assistants, telephony, meeting transcriptions, and any application needing low-latency speech-to-text. If you want to quickly add communication features to your app, an
embed video calling sdk
offers a straightforward way to integrate video and audio calls with minimal setup.Integration with Telephony and Servers (WebSocket/GRPC)
You can deploy Vosk as a server, exposing WebSocket or GRPC endpoints for scalable, multi-client speech recognition. This makes it suitable for telephony platforms, call centers, and backend voice analytics. For more advanced audio-video conferencing needs, integrating a
Video Calling API
can help you build scalable, feature-rich communication platforms.Example: Basic Vosk API Usage in Python
1from vosk import Model, KaldiRecognizer
2import wave
3
4model = Model("model")
5wf = wave.open("audio.wav", "rb")
6rec = KaldiRecognizer(model, wf.getframerate())
7
8while True:
9 data = wf.readframes(4000)
10 if len(data) == 0:
11 break
12 if rec.AcceptWaveform(data):
13 print(rec.Result())
14Integration Flow Diagram

Vosk Speech Recognition Models & Accuracy
Downloading & Using Language Models
Vosk speech recognition relies on downloadable language models, available from the
official Vosk models page
. Choose models based on your language, accuracy, and hardware requirements.Model Size vs. Accuracy Trade-offs
Smaller models (e.g., for Raspberry Pi) offer lower resource usage but may sacrifice some accuracy. Larger models provide higher accuracy and vocabulary coverage but require more memory and CPU.
Adaptation & Custom Vocabulary
Vosk allows customization of vocabulary to improve recognition accuracy for domain-specific terms and names.
Loading a Model and Using Custom Vocabulary (Python)
1from vosk import Model, KaldiRecognizer
2import wave
3
4model = Model("model")
5wf = wave.open("audio.wav", "rb")
6rec = KaldiRecognizer(model, wf.getframerate(), '["hello", "world", "vosk", "speech", "recognition"]')
7
8while True:
9 data = wf.readframes(4000)
10 if len(data) == 0:
11 break
12 if rec.AcceptWaveform(data):
13 print(rec.Result())
14Real-World Use Cases for Vosk Speech Recognition
Mobile Applications (Android/iOS)
Vosk speech recognition powers offline voice assistants, dictation apps, and accessibility tools on mobile devices. Its compact models enable real-time transcription without draining battery or requiring connectivity. For cross-platform mobile development, integrating a
react native video and audio calling sdk
can help you add high-quality communication features to your React Native apps.IoT & Edge Devices (Raspberry Pi)
Vosk's lightweight footprint makes it ideal for IoT and edge devices like Raspberry Pi. Developers build smart home controllers, voice-triggered automation, and embedded voice interfaces using Vosk. If you’re building voice-enabled rooms or collaborative spaces, leveraging a
Voice SDK
can facilitate real-time audio interactions in your IoT projects.Server-Side Processing & Telephony
In telephony, Vosk speech recognition is deployed for automated call transcription, voicemail analysis, and speech analytics, all running on-premises or in private clouds for data security.
Comparing Vosk Speech Recognition to Other Toolkits
Vosk vs Whisper ASR
- Vosk: True offline, open source, fast on CPUs, lightweight models
- Whisper: Open source, high accuracy, GPU recommended, larger models
Vosk vs Google Speech-to-Text
| Feature | Vosk Speech Recognition | Google Speech-to-Text |
|---|---|---|
| Offline Support | Yes | No |
| Open Source | Yes | No |
| Language Support | 20+ | 100+ |
| Model Size | Small (50MB+) | N/A (cloud) |
| Custom Vocabulary | Yes | Yes |
| Privacy | High | Depends |
| Cost | Free | Paid/Free Tier |
Troubleshooting & Tips for Vosk Speech Recognition
Common Installation Issues
- Ensure Python version compatibility
- Download correct model version for your device
- For Android/iOS, use official sample apps for reference
Improving Accuracy & Performance
- Use larger models if hardware allows
- Adapt models with domain-specific vocabulary
- Preprocess audio: reduce noise, use 16kHz mono WAV files
Community Support & Resources
Conclusion: Why Choose Vosk Speech Recognition?
Vosk speech recognition offers developers a unique blend of offline capability, open source flexibility, and ease of integration. Its lightweight models, extensive language support, and real-time APIs make it a top choice for 2025 speech-to-text applications across devices and industries. Dive in, experiment, and contribute to the thriving Vosk community—your next voice-enabled project awaits!
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ