Introduction to ASR Speech Recognition
Automatic Speech Recognition (ASR) speech recognition has rapidly become an essential technology in 2025, quietly powering many of the devices and applications we engage with daily. From virtual assistants to real-time meeting transcription, the ability to convert spoken language into accurate text is transforming the way we interact with computers and digital systems. As deep learning and neural networks advance, ASR speech recognition is achieving unprecedented accuracy, accessibility, and utility across industries.
What is ASR Speech Recognition?
ASR speech recognition, or automatic speech recognition, is the process by which computer systems convert spoken language into written text. While often used interchangeably, ASR, speech-to-text, and voice recognition have nuanced differences:
- ASR (Automatic Speech Recognition): Focuses on transcribing spoken audio to text.
- Speech-to-Text: Synonymous with ASR, describing the end result of transcribed audio.
- Voice Recognition: More broadly refers to identifying or verifying speakers, which can include authentication.
Common use cases for ASR speech recognition include:
- Virtual Assistants: Powering Siri, Alexa, and Google Assistant
- Transcription Services: Automated captioning for video content and meetings
- Accessibility: Enabling communication for users with hearing or speech impairments
- Contact Centers: Real-time transcription and analytics
In many of these scenarios, developers rely on solutions like a
Voice SDK
to integrate speech recognition and voice features into their applications, enhancing user experience and accessibility.How Does ASR Speech Recognition Work?
At its core, ASR speech recognition is a complex pipeline that processes raw speech data and outputs accurate text. Modern systems leverage deep learning and neural networks, but the fundamental stages remain consistent.
Audio Preprocessing and Feature Extraction
The process begins with audio preprocessing, where raw audio is cleaned, normalized, and enhanced to reduce noise and improve clarity. Next, feature extraction transforms the audio waveform into a sequence of numerical features—commonly Mel-frequency cepstral coefficients (MFCCs) or spectrograms—that represent the speech content in a form suitable for machine learning models.
For developers building audio applications, using a
python video and audio calling sdk
can streamline the integration of audio capture and preprocessing pipelines, making it easier to feed high-quality audio into ASR systems.Acoustic Modeling in ASR Speech Recognition
The acoustic model maps these extracted features to phonemes—the smallest units of sound in language. Modern models use deep neural networks to capture complex relationships between audio features and phonemes, outperforming traditional Hidden Markov Models (HMMs) by learning directly from vast amounts of labeled speech data.
Language Modeling and Decoding
Language models predict the most likely sequence of words based on context, using statistical n-grams, RNNs, or transformer architectures. The decoder combines the outputs of the acoustic and language models to generate the final transcription, resolving ambiguities and correcting errors using contextual information.
For web-based applications, integrating a
javascript video and audio calling sdk
can help developers capture and process real-time audio streams, which are essential for accurate ASR and seamless user experiences.End-to-End Deep Learning ASR Models
Contemporary ASR speech recognition systems often use end-to-end models—such as transformers and RNNs with Connectionist Temporal Classification (CTC)—that learn to map audio directly to text, reducing the need for handcrafted components and achieving state-of-the-art results.
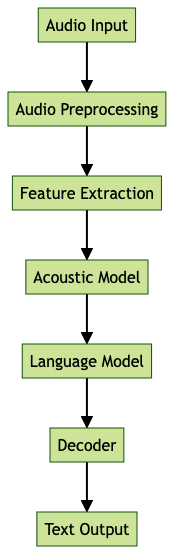
Key Components of ASR Speech Recognition Systems
Modern ASR speech recognition systems are composed of several key components that collaborate to achieve high transcription accuracy:
Acoustic Model
The acoustic model translates audio features into a sequence of phonemes or subword units. Deep neural networks, including CNNs, RNNs, and transformers, have largely replaced traditional GMM-HMM approaches, allowing for better generalization across accents and environments.
Language Model
The language model uses statistical (n-gram) or neural (RNN, transformer) approaches to predict word sequences based on context. It helps the ASR system resolve ambiguities and improves overall transcription accuracy by considering likely word patterns.
Decoder
The decoder integrates outputs from the acoustic and language models, using algorithms like beam search to find the most probable word sequence. It balances the likelihoods from both models to produce the final text.
Integration with NLP
Natural language processing (NLP) enhances ASR speech recognition by enabling tasks like punctuation restoration, entity recognition, and intent detection. Seamless integration with downstream NLP systems allows for richer, contextualized outputs and more sophisticated speech-driven applications.
For applications that require both video and audio communication, leveraging a
Video Calling API
can provide the necessary infrastructure to support real-time, high-quality interactions alongside ASR capabilities.Implementing ASR Speech Recognition: Code Example (Python)
Developers can leverage powerful open-source libraries to implement ASR speech recognition. Below is an example using NVIDIA NeMo, a popular toolkit for building ASR models in Python:
1import nemo.collections.asr as nemo_asr
2
3# Instantiate a pre-trained ASR model
4asr_model = nemo_asr.models.EncDecCTCModel.from_pretrained(
5 model_name="stt_en_conformer_ctc_small"
6)
7
8# Transcribe an audio file
9transcription = asr_model.transcribe(["sample.wav"])
10print("\"Transcription:\"", transcription[0])
11Walkthrough:
- Import the NeMo ASR collection
- Load a pre-trained end-to-end ASR model (Conformer-CTC)
- Transcribe an audio file directly to text
- Print the resulting transcription
This approach enables developers to quickly prototype and deploy ASR speech recognition in Python applications. For those looking to
embed video calling sdk
features alongside ASR, prebuilt solutions can further accelerate development and deployment.Evaluating ASR Speech Recognition Accuracy
A critical metric in ASR speech recognition is the Word Error Rate (WER), which quantifies transcription errors as a percentage:
1WER = (Substitutions + Deletions + Insertions) / Total Words × 100%
2Benchmarks like LibriSpeech and TED-LIUM provide standardized datasets to compare ASR system performance. Achieving low WER is challenging, especially with domain-specific vocabulary, regional accents, or noisy audio.
Key challenges:
- Accents and Dialects: Variability can increase error rates
- Background Noise: Impacts feature extraction and model accuracy
- Terminology: Domain-specific jargon often requires model adaptation
Continuous model training and evaluation are essential for maintaining high transcription accuracy in real-world deployments. In industries like telecommunications, integrating a
phone call api
can facilitate seamless voice communication and support accurate ASR transcription in call scenarios.Popular ASR Speech Recognition Providers & Open Source Tools
ASR speech recognition is accessible through a range of cloud APIs and open-source frameworks:
Major Cloud APIs
- Google Cloud Speech-to-Text: Real-time, multilingual transcription with powerful APIs
- AWS Transcribe: Scalable, customizable ASR capabilities for enterprises
- IBM Watson Speech to Text: Advanced acoustic and language modeling
- Microsoft Azure Speech: Unified APIs for speech-to-text, translation, and speaker diarization
For developers seeking to add real-time audio and video features to their products, a
Voice SDK
can provide robust APIs and tools for rapid integration.Open Source Solutions
- NVIDIA NeMo: Modular, extensible toolkit for state-of-the-art ASR
- Mozilla DeepSpeech: Open-source, deep learning ASR engine
- Kaldi: Popular research-focused toolkit for academic and commercial use
These options empower developers to build, customize, and deploy ASR speech recognition for a wide range of applications. Additionally, integrating a
Video Calling API
can enhance collaboration platforms by combining speech recognition with live video and audio communication.Real-World Applications and Industry Use Cases
ASR speech recognition is transforming industries by automating and augmenting speech-driven workflows:
- Healthcare: Real-time clinical documentation, voice-driven EHR interfaces
- Contact Centers: Automated call transcription, sentiment analysis, compliance monitoring
- Accessibility: Live captioning for the hearing impaired, voice-controlled interfaces
- Media & Entertainment: Automated subtitles, podcast transcription, video indexing
- Virtual Assistants: Smart home control, task automation, contextual responses
For example, healthcare providers leverage ASR speech recognition to reduce administrative burden, while media companies use it to generate searchable archives of audio and video content. Many of these solutions are powered by a
Voice SDK
, which enables seamless integration of voice features into diverse applications.Challenges & Future Trends in ASR Speech Recognition
Despite advances, ASR speech recognition faces ongoing challenges:
- Privacy & Security: Safeguarding sensitive speech data and ensuring compliance with data protection regulations
- Multilingual & Code-Switching: Supporting seamless transitions between languages and dialects in real time
- Emerging Research: Self-supervised learning, zero-shot adaptation, and transformer models are driving progress toward more robust, generalizable systems
Future trends include edge deployment for privacy, real-time streaming, and deeper integration with NLP for richer, context-aware applications. Leveraging a
Voice SDK
will continue to play a pivotal role as developers seek to build more interactive and intelligent voice-enabled products.Conclusion: The Future of ASR Speech Recognition
ASR speech recognition in 2025 is more accurate, accessible, and versatile than ever before. Driven by deep learning, large-scale datasets, and open-source innovation, ASR technology is unlocking new possibilities for human-computer interaction, accessibility, and automation across every industry. As research advances, expect even greater accuracy, privacy, and multilingual support in the years ahead.
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ