Introduction to Voice Agents with LLMs
Voice agents are intelligent software systems capable of understanding and responding to spoken language, enabling seamless human-computer interaction. At the core of the latest advancements in voice agents are large language models (LLMs), which leverage deep learning to process and generate human-like text. Together, these technologies power next-generation conversational AI, delivering natural, context-aware experiences across devices and applications.
In 2025, the landscape of voice agents with LLMs is flourishing, thanks to open-source and commercial advancements. Tools like OpenAI Whisper and AssemblyAI offer state-of-the-art speech-to-text (STT) capabilities, while ElevenLabs and Bark deliver expressive text-to-speech (TTS) synthesis. LLMs—whether accessed via OpenAI APIs, local deployments with Ollama, or frameworks such as LangChain—bring unprecedented fluency to voice-driven applications. This ecosystem empowers developers to build robust, real-time voice agents with LLMs for a multitude of use cases.
Why Build Voice Agents with LLMs?
Building voice agents with LLMs unlocks transformative benefits compared to traditional voice assistants. LLMs provide greater language understanding, enabling more natural, contextually relevant conversations. This results in hands-free, human-like interactions that can adapt to user intent and offer personalized responses.
Industry adoption is accelerating across customer service, healthcare, smart homes, and enterprise automation, as organizations leverage voice agents with LLMs to streamline workflows and enhance user experiences. For developers, this surge presents vast opportunities: from creating multimodal virtual assistants to deploying automation in IoT devices, the flexibility and open-source nature of LLM-based solutions empower rapid innovation and customization. Integrating a
Voice SDK
can further simplify the process of adding real-time voice features to your applications, making it easier to build scalable and interactive voice agents.Voice Agent Architecture: Core Components
Building robust voice agents with LLMs requires understanding the core architectural components:
Speech-to-Text (STT)
Speech-to-text converts spoken language into machine-readable text. Modern STT engines, such as Whisper and AssemblyAI, utilize transformer models for high accuracy and real-time processing. Developers can leverage these APIs or run models locally to transcribe user input, forming the first step of the conversational pipeline. For those looking to add audio and video capabilities, consider using a
python video and audio calling sdk
to enable seamless communication features alongside your voice agent.Language Model Processing
Once the user's speech is transcribed, LLMs process the text to comprehend context and generate appropriate replies. Solutions range from cloud-based APIs (OpenAI, Cohere) to local LLMs running via Ollama or custom deployments. Frameworks like LangChain facilitate complex workflows, integrating LLM responses with external data (RAG) or multi-agent orchestration. Developers seeking to integrate calling features can explore a
phone call api
to add telephony and real-time voice communication to their voice agents.Text-to-Speech (TTS)
After the agent generates a response, TTS synthesizes human-like speech for playback. ElevenLabs, Bark, and Python libraries like pyttsx3 offer various voices, emotional nuances, and deployment options, making TTS integration flexible and accessible. To further enhance user experience, leveraging an
embed video calling sdk
can provide seamless video and audio integration within your application.Real-Time Conversational Flow in Voice Agents with LLMs
A typical real-time conversational flow in voice agents with LLMs involves several steps:
- Voice Input: The user speaks into a microphone.
- STT Processing: Speech is transcribed into text (Whisper, AssemblyAI).
- LLM Processing: Transcribed text is analyzed and a response is generated (Ollama, OpenAI, local LLMs).
- TTS Synthesis: The response is converted back to speech (ElevenLabs, pyttsx3).
- Voice Output: The synthesized voice is played back to the user.
Latency management and robust error handling are crucial for smooth, real-time conversations. Developers must optimize model selection, API calls, and hardware acceleration (e.g., GPU support) to meet user expectations. Utilizing a
Voice SDK
can help streamline these processes, offering built-in tools for real-time audio management and low-latency communication.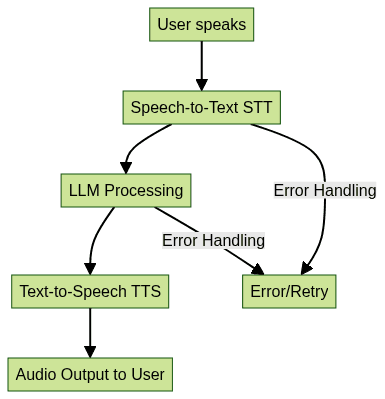
Implementing a Voice Agent with LLMs: Step-by-Step Tutorial
1. Setting Up the Environment
To start building voice agents with LLMs, set up a Python environment and install required dependencies. Recommended tools include
openai-whisper, openai, elevenlabs, and pyttsx3.1pip install openai-whisper openai elevenlabs pyttsx3 sounddevice
2Or, using conda:
1conda create -n voice-agent python=3.10
2conda activate voice-agent
3pip install openai-whisper openai elevenlabs pyttsx3 sounddevice
42. Integrating Speech-to-Text (STT)
Let's use OpenAI Whisper for STT. Record audio and transcribe it in Python:
1import whisper
2import sounddevice as sd
3import numpy as np
4
5fs = 16000
6seconds = 5
7print("Speak now...")
8recording = sd.rec(int(seconds * fs), samplerate=fs, channels=1, dtype=np.int16)
9sd.wait()
10
11model = whisper.load_model("base")
12result = model.transcribe(np.squeeze(recording).astype(np.float32))
13print("You said:", result["text"])
143. Connecting to an LLM
Send the transcribed text to an LLM (e.g., OpenAI API):
1import openai
2openai.api_key = "YOUR_OPENAI_API_KEY"
3
4response = openai.ChatCompletion.create(
5 model="gpt-3.5-turbo",
6 messages=[{"role": "user", "content": result["text"]}]
7)
8reply = response["choices"][0]["message"]["content"]
9print("Agent reply:", reply)
10For local LLMs, you can use Ollama:
1import requests
2ollama_url = "http://localhost:11434/api/generate"
3payload = {"model": "llama2", "prompt": result["text"]}
4response = requests.post(ollama_url, json=payload)
5reply = response.json()["response"]
6print("Agent reply:", reply)
74. Text-to-Speech Synthesis
Convert the LLM's reply to speech using ElevenLabs:
1from elevenlabs import generate, play, set_api_key
2set_api_key("YOUR_ELEVENLABS_API_KEY")
3
4audio = generate(
5 text=reply,
6 voice="Rachel",
7 model="eleven_multilingual_v2"
8)
9play(audio)
10Or, for an open-source/local option:
1import pyttsx3
2engine = pyttsx3.init()
3engine.say(reply)
4engine.runAndWait()
55. Orchestrating the Conversation Loop
Combine all components into a main loop to create a real-time voice agent with LLMs. Add error handling and maintain context for continuity.
1import whisper
2import openai
3import pyttsx3
4import sounddevice as sd
5import numpy as np
6
7openai.api_key = "YOUR_OPENAI_API_KEY"
8fs = 16000
9model = whisper.load_model("base")
10engine = pyttsx3.init()
11context = []
12
13while True:
14 print("Speak now...")
15 recording = sd.rec(int(5 * fs), samplerate=fs, channels=1, dtype=np.int16)
16 sd.wait()
17 try:
18 stt_result = model.transcribe(np.squeeze(recording).astype(np.float32))
19 user_text = stt_result["text"]
20 if not user_text.strip():
21 print("No input detected.")
22 continue
23 print("You said:", user_text)
24 context.append({"role": "user", "content": user_text})
25 response = openai.ChatCompletion.create(
26 model="gpt-3.5-turbo",
27 messages=context[-10:] # Keep last 10 exchanges for context
28 )
29 reply = response["choices"][0]["message"]["content"]
30 print("Agent reply:", reply)
31 context.append({"role": "assistant", "content": reply})
32 engine.say(reply)
33 engine.runAndWait()
34 except Exception as e:
35 print(f"Error: {e}")
36 engine.say("Sorry, I didn\'t catch that.")
37 engine.runAndWait()
38Advanced Features & Customization in Voice Agents with LLMs
Developers can extend voice agents with LLMs by applying prompt engineering for tailored responses, context adaptation, and specialized knowledge. Multi-agent systems and retrieval-augmented generation (RAG) enable agents to pull in up-to-date information from databases or APIs, boosting accuracy and relevance. For advanced communication features, integrating a
Video Calling API
allows you to add high-quality video and audio conferencing to your voice agent applications.Personality and emotion can be infused into responses through prompt design and TTS features (e.g., voice tone, language). Multilingual support is achievable via LLM and TTS models trained on diverse datasets. For privacy-sensitive use cases, deploying local LLMs with Ollama or running STT/TTS models offline ensures data never leaves the device, addressing compliance and security needs. Additionally, using a
Voice SDK
can help you implement secure, scalable voice communication channels for your applications.Challenges and Best Practices for Voice Agents with LLMs
Voice agents with LLMs face challenges such as latency, especially with real-time requirements. Optimize by selecting efficient models, using GPU acceleration, and minimizing API round-trips. Privacy is another key concern—prefer local processing or encrypted API calls. Comprehensive error handling, clear feedback, and accessibility features (e.g., speech customization, adaptive UI) are vital for robust user experiences, especially in production deployments. For telephony integration, a
phone call api
can provide direct calling capabilities, expanding the reach and utility of your voice agent.Future Trends in Voice Agents with LLMs
As we progress through 2025, expect rapid advances in speech-native models and multimodal APIs capable of handling voice, text, and images. Voice agents with LLMs will see further improvements in real-time performance, context awareness, and emotional intelligence. Industry adoption will broaden, making conversational AI a default interface for devices, apps, and services. Developers can leverage a
Voice SDK
to stay ahead of these trends and ensure their solutions are future-ready.Conclusion
Building voice agents with LLMs empowers developers to deliver natural, intuitive, and powerful conversational experiences. As the ecosystem matures, open-source tools and APIs make it easier than ever to prototype, customize, and deploy your own intelligent voice agents.
Try it for free
and start experimenting today to shape the future of human-computer interaction.Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ