Introduction: The Rise of Real-Time Voice to Text
In today's fast-paced world, the ability to convert speech to text in real-time is transforming how we communicate, work, and access information. Real-time voice to text, also known as real-time speech to text or live transcription, is revolutionizing industries ranging from media and entertainment to healthcare and education. This technology provides instant accessibility, improves productivity, and enables innovative applications that were once considered science fiction. This blog post dives deep into the world of real-time voice to text, exploring its underlying technologies, top software options, and future trends.
What is Real-Time Voice to Text?
Real-time voice to text is the process of instantly converting spoken words into written text as they are being spoken. Unlike traditional dictation software that processes audio after it has been recorded, real-time voice to text operates instantaneously, providing a live transcription of the speech.
The Growing Demand for Real-Time Transcription
The demand for real-time transcription is rapidly increasing due to its numerous benefits. It provides accessibility for individuals with hearing impairments, enables live captioning for video conferences and webinars, and streamlines note-taking during meetings and lectures. Moreover, it facilitates efficient communication in noisy environments and allows for hands-free operation in various tasks. The need for accurate, efficient, and readily available voice-to-text solutions is paramount across diverse sectors.
Applications Across Industries
Real-time voice to text is finding applications across various industries. In media, it powers live subtitling for broadcasts and online streaming. In healthcare, it assists doctors in documenting patient interactions. In education, it supports students with note-taking and provides accessible learning materials. Furthermore, it's used in call centers for real-time agent assistance and in legal settings for court reporting. The breadth of applications is vast and continuously expanding.
How Real-Time Voice to Text Works: A Deep Dive
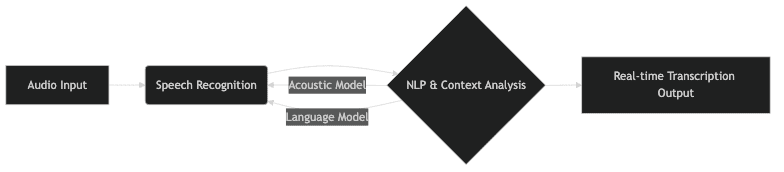
Real-time voice to text is a complex process involving multiple technologies working in concert. The core components include speech recognition, natural language processing (NLP), acoustic modeling, and language modeling. Understanding these elements is crucial for developers looking to implement or optimize voice-to-text solutions.
Speech Recognition: The Core Technology
Speech recognition is the fundamental technology that converts audio signals into textual data. It involves breaking down the audio into smaller units called phonemes and then identifying the most likely sequence of words based on these phonemes. Advanced speech recognition systems utilize machine learning models trained on vast amounts of audio data to achieve high accuracy. These models are capable of adapting to different accents, speaking styles, and background noise.
1// Example of a simple speech recognition request using the Web Speech API
2const recognition = new webkitSpeechRecognition();
3recognition.lang = 'en-US';
4recognition.interimResults = false;
5recognition.maxAlternatives = 1;
6
7recognition.onresult = function(event) {
8 const speechResult = event.results[0][0].transcript;
9 console.log('Confidence: ' + event.results[0][0].confidence);
10 console.log('Result: ' + speechResult);
11}
12
13recognition.onerror = function(event) {
14 console.error('Speech recognition error detected: ' + event.error);
15}
16
17recognition.start();
18Natural Language Processing (NLP): Understanding Context
Natural Language Processing (NLP) plays a critical role in enhancing the accuracy and coherence of real-time voice to text. NLP techniques analyze the context of the transcribed text to correct errors, disambiguate words, and improve overall readability. For instance, NLP can identify and correct homophones (words that sound alike but have different meanings) based on the surrounding words. This process significantly enhances the quality of the final output.
Acoustic Modeling and Language Modeling
Acoustic modeling and language modeling are two key components that work together to improve the accuracy of speech recognition. Acoustic models map phonemes to audio signals, while language models predict the probability of word sequences based on linguistic patterns. By combining these two models, real-time voice-to-text systems can accurately transcribe speech even in challenging acoustic environments.
1# Illustrative Python code snippet showcasing NLP techniques for context analysis using NLTK
2import nltk
3from nltk.corpus import stopwords
4from nltk.tokenize import word_tokenize
5
6text = "The weather is nice today. Let's go to the beach."
7
8stop_words = set(stopwords.words('english'))
9word_tokens = word_tokenize(text)
10
11filtered_sentence = [w for w in word_tokens if not w.lower() in stop_words]
12
13print(filtered_sentence)
14Real-Time Processing Challenges and Solutions
Real-time processing introduces significant challenges, including latency, computational demands, and the need for robust error handling. Solutions often involve optimized algorithms, distributed processing, and specialized hardware. Maintaining accuracy while minimizing latency is a constant balancing act in the design of real-time voice-to-text systems.
Top Real-Time Voice to Text Software and APIs
A variety of real-time voice-to-text software and APIs are available, each with its own strengths and weaknesses. The choice of which solution to use depends on specific requirements, such as accuracy, language support, cost, and integration capabilities. Below are some of the leading options.
Google Cloud Speech-to-Text
Google Cloud Speech-to-Text offers high accuracy and supports a wide range of languages. It leverages Google's advanced machine learning models to provide real-time transcription with low latency. The API is highly scalable and can be integrated into various applications, making it a popular choice for developers.
1# Simple code example integrating Google Cloud Speech-to-Text API
2from google.cloud import speech
3
4client = speech.SpeechClient()
5
6with open("audio.raw", "rb") as audio_file:
7 content = audio_file.read()
8
9audio = speech.RecognitionAudio(content=content)
10config = speech.RecognitionConfig(
11 encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
12 sample_rate_hertz=16000,
13 language_code="en-US",
14)
15
16response = client.recognize(config=config, audio=audio)
17
18for result in response.results:
19 print("Transcript: {}".format(result.alternatives[0].transcript))
20Amazon Transcribe
Amazon Transcribe is another robust real-time speech-to-text service that offers high accuracy and scalability. It integrates seamlessly with other AWS services, making it a convenient option for developers already using the Amazon ecosystem. Amazon Transcribe also supports custom vocabulary and acoustic models to improve accuracy in specific domains.
Microsoft Azure Speech to Text
Microsoft Azure Speech to Text provides real-time transcription capabilities with a focus on enterprise-grade security and compliance. It offers advanced features such as speaker diarization and sentiment analysis. Its integration with other Azure services makes it a compelling option for organizations using the Microsoft cloud platform.
AssemblyAI
AssemblyAI offers a powerful and developer-friendly speech-to-text API with a focus on accuracy and ease of use. They provide features like speaker diarization, entity detection, and content moderation. AssemblyAI's API is designed to be simple to integrate, making it a good choice for rapid development and prototyping.
Other Notable Options (Open-Source and Commercial)
Besides the major cloud providers, several other notable options exist. These include open-source solutions like CMU Sphinx and Kaldi, as well as commercial alternatives such as Deepgram and Otter.ai. Open-source solutions offer greater flexibility and customization, while commercial options often provide higher accuracy and dedicated support.
Choosing the Right Real-Time Voice to Text Solution
Selecting the appropriate real-time voice-to-text solution requires careful consideration of various factors. These include accuracy, features, cost, integration capabilities, and scalability. A thorough evaluation of these aspects will ensure that the chosen solution meets the specific needs of the application.
Factors to Consider: Accuracy, Features, Cost, and Integration
Accuracy is paramount, particularly in applications where precise transcription is critical. Features such as speaker diarization, language support, and custom vocabulary can significantly enhance the utility of a solution. Cost is another important factor, especially for large-scale deployments. Finally, ease of integration with existing systems and workflows is crucial for seamless implementation.
Accuracy and Language Support
Accuracy rates vary across different solutions, and it's essential to test performance with representative audio samples. Language support is also critical, especially for applications that need to transcribe multiple languages. Evaluate the available language models and ensure they cover the required languages and dialects.
Scalability and API Limitations
Scalability is a key consideration for applications that anticipate high volumes of transcription. Check the API rate limits and ensure they meet the expected demand. Understanding the scalability limitations of a solution is vital to avoid performance bottlenecks.
Cost-Effectiveness and Pricing Models
Real-time voice-to-text services typically offer various pricing models, such as pay-per-minute, subscription-based, or custom pricing. Analyze the pricing structure and determine the most cost-effective option based on usage patterns and budget constraints.
Future Trends and Advancements in Real-Time Voice to Text
The field of real-time voice-to-text is rapidly evolving, driven by advancements in artificial intelligence and machine learning. Future trends include enhanced accuracy, reduced latency, improved language support, and integration with other AI technologies. These advancements will further expand the applications and impact of real-time voice-to-text.
Enhanced Accuracy and Reduced Latency
Ongoing research is focused on improving the accuracy of speech recognition models, particularly in noisy environments and with diverse accents. Reducing latency is another key goal, as faster transcription enables more seamless and responsive applications. Innovations in acoustic modeling and language modeling are contributing to these improvements.
Improved Language Support and Multilingual Capabilities
The development of more robust and comprehensive language models is expanding the language support offered by real-time voice-to-text services. Multilingual capabilities are also improving, enabling seamless transcription of conversations that switch between different languages.
Integration with other AI Technologies
Real-time voice to text is increasingly being integrated with other AI technologies, such as machine translation, sentiment analysis, and natural language understanding. This integration enables more sophisticated applications, such as real-time translation of spoken conversations and automated analysis of customer feedback.
The Role of AI in Personalization and Customization
AI is playing a crucial role in personalizing and customizing real-time voice-to-text solutions. Custom voice models can be trained to improve accuracy for specific users, accents, or domains. Personalization enhances the utility and effectiveness of voice-to-text in various contexts.
Conclusion: The Impact of Real-Time Voice to Text on Communication and Productivity
Real-time voice to text is transforming communication and productivity across various industries. From enabling accessibility for individuals with disabilities to streamlining workflows in businesses, this technology is having a profound impact. As AI continues to advance, real-time voice to text will become even more accurate, efficient, and versatile, further expanding its applications and benefits.
- Learn more about
Google Cloud Speech-to-Text
- Explore
Amazon Transcribe
- Discover
Microsoft Azure Speech to Text
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ