Introduction to Realtime OpenAI
In today's software landscape, speed and efficiency are non-negotiable. "Realtime OpenAI" refers to leveraging OpenAI's APIs and infrastructure to deliver instant, live AI-powered experiences in modern applications. By enabling low-latency interactions—whether it's a chatbot, voice assistant, or data-driven agent—OpenAI's realtime offerings set a new standard for developer productivity and user engagement. The ability to process live data and return responses without perceptible delay is transforming AI from a background process to a core interactive capability, powering the next wave of agentic and tool-augmented applications.
Understanding Realtime in OpenAI APIs
What Makes OpenAI APIs Realtime?
In the context of OpenAI, "realtime" means the ability to process input and deliver output with minimal delay, often using streaming responses. This is crucial for applications like live chat, coding assistants, or voice agents, where user experience hinges on instant feedback. Traditional AI workflows were batch-oriented, with significant wait times for inference or processing. Realtime OpenAI APIs, in contrast, provide:
- Live data processing: Handle user input as it arrives, enabling dynamic, interactive sessions.
- Instant responses: Stream output tokens as soon as they are generated, reducing perceived latency.
- Streaming APIs: Continuous delivery of responses instead of waiting for a complete output.
Comparison: Traditional vs. Realtime AI Workflows
| Feature | Traditional LLM Workflow | Realtime OpenAI API |
|---|---|---|
| Latency | High (seconds+) | Low (sub-second to ~1 sec) |
| Data Handling | Batch, static | Streaming, live |
| User Experience | Delayed, async | Instant, interactive |
| Integration Flexibility | Limited | High (supports tool usage) |
OpenAI Responses API Overview
The OpenAI Responses API unlocks these realtime capabilities. Key features include:
- Token streaming: Partial responses are sent as soon as available.
- Tool integration: Invoke third-party APIs and tools in realtime.
- Event hooks: Trigger actions or updates based on streaming progress.
- Low-latency optimizations: Engineered for sub-second round-trip times.
Recent updates have improved agentic reliability, introduced reasoning tokens (for tracing decision logic), and enhanced security for enterprise use cases. These evolutions make the Responses API central to any realtime AI deployment.
Building Realtime Agentic Applications
Agentic Applications and Realtime Needs
Agentic applications are software entities that can reason, act, and interact with their environment or users autonomously. Examples include:
- Voice AI agents: Conversational interfaces for customer support or personal assistance.
- Coding agents: Pair programmers or code reviewers that respond instantly to developer queries.
- Market intelligence bots: Analyze live data and provide up-to-the-minute insights.
For these agents, realtime response is not just a luxury—it's a necessity. The effectiveness of an AI agent is judged by its ability to react and adapt instantly, making low latency and seamless tool integration foundational requirements.
Realtime OpenAI Agent Architecture
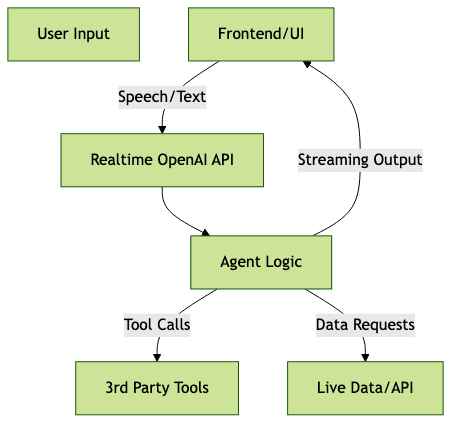
Case Study: Building a Voice AI Agent (with code snippet)
Let's walk through building a basic voice AI agent using the Realtime OpenAI Responses API. This agent listens for user voice input, transcribes it, sends it to OpenAI, and streams the AI's response back as speech.
[Code Snippet] Voice AI Agent Setup
1import openai
2import speech_recognition as sr
3import pyttsx3
4
5openai.api_key = "YOUR_OPENAI_API_KEY"
6
7# Initialize speech recognition and text-to-speech
8recognizer = sr.Recognizer()
9engine = pyttsx3.init()
10
11print("Say something...")
12with sr.Microphone() as source:
13 audio = recognizer.listen(source)
14 user_input = recognizer.recognize_google(audio)
15 print(f"User said: {user_input}")
16
17 # Stream response from OpenAI
18 response = openai.ChatCompletion.create(
19 model="gpt-4o",
20 messages=[{"role": "user", "content": user_input}],
21 stream=True
22 )
23 print("AI: ", end="")
24 for chunk in response:
25 if "choices" in chunk:
26 content = chunk["choices"][0]["delta"].get("content", "")
27 print(content, end="", flush=True)
28 engine.say(content)
29 engine.runAndWait()
30This example highlights how low-latency streaming is essential for natural dialogue in voice applications—no more awkward pauses or delays.
Integrating Third-Party Tools with Remote MCP Servers
What is MCP? Why Does it Matter for Realtime?
The Model Context Protocol (MCP) is an open standard that enables LLMs like OpenAI's models to call external APIs, tools, or data sources in-context and in realtime. Instead of relying solely on pre-trained knowledge, agents can:
- Fetch live data (stock prices, weather, search results)
- Execute code or scripts on demand
- Integrate with enterprise backends securely
Remote MCP servers act as bridges between OpenAI's API and third-party systems, dramatically expanding what agents can do in a live session.
MCP Server Integration Workflow

Example: Connecting OpenAI to a Remote MCP Server (code snippet)
Suppose you want your OpenAI agent to fetch live weather data via a third-party MCP server:
[Code Snippet] MCP Server Integration
1import openai
2import requests
3
4def call_mcp_tool(user_query):
5 # Simulate MCP tool invocation
6 mcp_payload = {
7 "input": user_query,
8 "tool": "weather_api"
9 }
10 mcp_response = requests.post(
11 "https://remote-mcp.example.com/invoke",
12 json=mcp_payload,
13 headers={"Authorization": "Bearer YOUR_MCP_API_KEY"}
14 )
15 return mcp_response.json()
16
17# Use OpenAI to determine when to call MCP
18def openai_with_mcp(user_input):
19 response = openai.ChatCompletion.create(
20 model="gpt-4o",
21 messages=[
22 {"role": "system", "content": "You may call the weather_api tool when needed."},
23 {"role": "user", "content": user_input}
24 ]
25 )
26 return response["choices"][0]["message"]["content"]
27
28user_input = "What\'s the weather in Berlin right now?"
29weather_data = call_mcp_tool(user_input)
30print("Weather:", weather_data)
31response = openai_with_mcp(user_input)
32print("AI Response:", response)
33Popular platforms that support MCP include Zapier, Microsoft Power Automate, and custom enterprise connectors. This pattern enables AI agents to orchestrate complex workflows across disparate systems in realtime.
New Tools and Features for Realtime Development
Image Generation, Code Interpreter, and Reasoning Summaries
OpenAI's latest toolset supercharges realtime workflows:
- Image Generation: Instantly generate visuals or diagrams in response to user prompts, ideal for education and content creation.
- Code Interpreter: Execute and debug code on the fly, dramatically improving developer productivity and data science workflows.
- Reasoning Summaries: Trace the agent's logic step-by-step for transparency and debuggability.
Example Use Cases:
- Education: Visualize concepts as students ask questions.
- Coding: Get instant code explanations and bug fixes during live coding sessions.
- Content Generation: Automated social media or marketing content with image assets.
Background Mode, Security, and Privacy Enhancements
- Background Mode: Allows agents to continue processing long-running tasks even if the primary session is paused or disconnected—a game-changer for reliability.
- Encrypted Reasoning: All reasoning tokens and tool calls can be end-to-end encrypted, ensuring privacy for sensitive workflows.
- Enterprise Privacy: Fine-grained controls over data retention, access logs, and API usage analytics, giving enterprises confidence in deploying OpenAI-powered solutions at scale.
Best Practices for Realtime OpenAI Implementations
Optimizing for Speed, Cost, and Security
- Reduce Latency: Use streaming APIs, select the closest OpenAI region, and minimize unnecessary tool calls.
- Token Management: Monitor and optimize token usage—stream only what the user needs, and leverage reasoning tokens for efficient debugging.
- Security: Always use HTTPS, validate tool integrations, and enable encrypted reasoning for sensitive applications.
- Cost Optimization: Batch tool calls when possible, use lower-cost models for non-critical paths, and monitor usage with OpenAI's analytics tools.
- Scalability: Design agents to gracefully degrade functionality if a tool or MCP server is unavailable.
Future of Realtime OpenAI and the Ecosystem
The MCP ecosystem is expanding rapidly, making it easier for developers to build rich, integrated realtime applications. As OpenAI continues to evolve its APIs—with features like multimodal reasoning, autonomous agent deployment, and deeper enterprise controls—new opportunities will emerge in sectors from finance to education to creative industries. The commitment to low-latency, secure, and privacy-respecting AI will continue to shape the developer ecosystem and the future of intelligent software.
Conclusion
Realtime OpenAI is reshaping what's possible with AI in modern applications. By combining live data, instant responses, and secure tool integrations, developers and enterprises can deliver next-generation user experiences. Start building with OpenAI's realtime APIs today to unlock new levels of productivity, creativity, and value for your users.
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ