Introduction to AI Voice Agents in Low Latency TTS
What is an AI Voice Agent
?
AI Voice Agents are sophisticated software systems designed to interact with users through voice commands. They process spoken language, convert it into text, understand the intent, and respond appropriately. These agents are becoming increasingly prevalent in various industries, offering automated customer support, virtual assistance, and more.
Why are they important for the low latency TTS industry?
In the realm of Text-to-Speech (TTS), low latency is crucial for providing seamless and natural interactions. AI Voice Agents with low latency TTS capabilities can deliver real-time responses, enhancing user experience in applications such as virtual assistants, customer service bots, and interactive voice response systems.
Core Components of a Voice Agent
- Speech-to-Text (STT): Converts spoken language into text.
- Large Language Model (LLM): Understands and processes the text to generate a response.
- Text-to-Speech (TTS): Converts the response text back into speech.
What You'll Build in This Tutorial
In this tutorial, you will build a low latency TTS AI
Voice Agent
using the VideoSDK framework. The agent will process real-time user inputs and respond with minimal delay, supporting multiple languages and offering natural-sounding voice outputs.Architecture and Core Concepts
High-Level Architecture Overview
The AI
Voice Agent
architecture involves a seamless flow of data from user speech to agent response. The process begins with capturing the user's voice, which is then converted into text using STT. The text is processed by an LLM to determine the appropriate response, which is finally converted back to speech using TTS.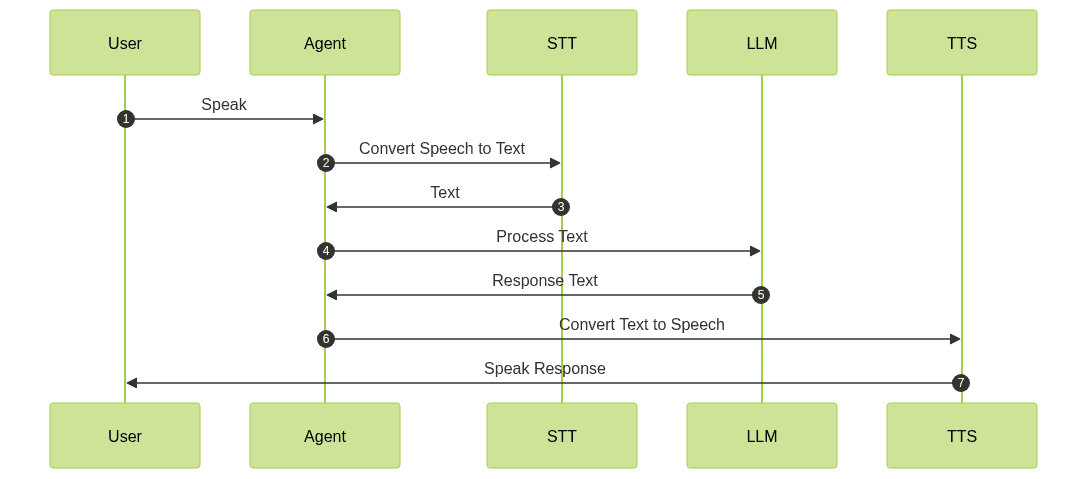
Understanding Key Concepts in the VideoSDK Framework
- Agent: This is the core class that represents your AI
Voice Agent
. It handles the interaction logic and manages the session lifecycle. Cascading Pipeline in AI voice Agents
: This component defines the flow of audio processing, orchestrating the STT, LLM, and TTS components to work together seamlessly.- VAD &
Turn Detector for AI voice Agents
: Voice Activity Detection (VAD) and Turn Detection are crucial for determining when the agent should listen and when it should respond, ensuring smooth interactions.
Setting Up the Development Environment
Prerequisites
Before you begin, ensure you have Python 3.11+ installed on your system. Additionally, you will need a VideoSDK account, which you can create at app.videosdk.live.
Step 1: Create a Virtual Environment
To manage dependencies and avoid conflicts, create a virtual environment:
1python -m venv myenv
2source myenv/bin/activate # On Windows use `myenv\Scripts\activate`
3Step 2: Install Required Packages
Install the necessary packages using pip:
1pip install videosdk
2Step 3: Configure API Keys in a .env file
Create a
.env file in your project directory and add your VideoSDK API keys:1VIDEOSDK_API_KEY=your_api_key_here
2Building the AI Voice Agent: A Step-by-Step Guide
Below is the complete, runnable code for the AI Voice Agent:
1import asyncio, os
2from videosdk.agents import Agent, [AgentSession](https://docs.videosdk.live/ai_agents/core-components/agent-session), CascadingPipeline, JobContext, RoomOptions, WorkerJob, ConversationFlow
3from videosdk.plugins.silero import SileroVAD
4from videosdk.plugins.turn_detector import TurnDetector, pre_download_model
5from videosdk.plugins.deepgram import DeepgramSTT
6from videosdk.plugins.openai import OpenAILLM
7from videosdk.plugins.elevenlabs import ElevenLabsTTS
8from typing import AsyncIterator
9
10# Pre-downloading the Turn Detector model
11pre_download_model()
12
13agent_instructions = "{\n \"persona\": \"Efficient Communication Assistant\",\n \"capabilities\": [\n \"Provide real-time text-to-speech conversion with minimal delay\",\n \"Support multiple languages for diverse user interactions\",\n \"Offer clear and natural-sounding voice outputs\",\n \"Adapt to user preferences for voice speed and tone\"\n ],\n \"constraints\": [\n \"You are not capable of understanding or processing medical or legal advice\",\n \"Ensure that all interactions are respectful and non-intrusive\",\n \"You must include a disclaimer that the TTS service is for informational purposes only and not a substitute for professional advice\",\n \"You should not store or retain any personal user data\"\n ]\n}"
14
15class MyVoiceAgent(Agent):
16 def __init__(self):
17 super().__init__(instructions=agent_instructions)
18 async def on_enter(self): await self.session.say("Hello! How can I help?")
19 async def on_exit(self): await self.session.say("Goodbye!")
20
21async def start_session(context: JobContext):
22 # Create agent and conversation flow
23 agent = MyVoiceAgent()
24 conversation_flow = ConversationFlow(agent)
25
26 # Create pipeline
27 pipeline = CascadingPipeline(
28 stt=DeepgramSTT(model="nova-2", language="en"),
29 llm=OpenAILLM(model="gpt-4o"),
30 tts=ElevenLabsTTS(model="eleven_flash_v2_5"),
31 vad=SileroVAD(threshold=0.35),
32 turn_detector=TurnDetector(threshold=0.8)
33 )
34
35 session = AgentSession(
36 agent=agent,
37 pipeline=pipeline,
38 conversation_flow=conversation_flow
39 )
40
41 try:
42 await context.connect()
43 await session.start()
44 # Keep the session running until manually terminated
45 await asyncio.Event().wait()
46 finally:
47 # Clean up resources when done
48 await session.close()
49 await context.shutdown()
50
51def make_context() -> JobContext:
52 room_options = RoomOptions(
53 # room_id="YOUR_MEETING_ID", # Set to join a pre-created room; omit to auto-create
54 name="VideoSDK Cascaded Agent",
55 playground=True
56 )
57
58 return JobContext(room_options=room_options)
59
60if __name__ == "__main__":
61 job = WorkerJob(entrypoint=start_session, jobctx=make_context)
62 job.start()
63Step 4.1: Generating a VideoSDK Meeting ID
To interact with your agent, you need a meeting ID. You can generate one using the VideoSDK API:
1curl -X POST \
2 'https://api.videosdk.live/v1/rooms' \
3 -H 'Authorization: Bearer YOUR_API_KEY' \
4 -H 'Content-Type: application/json' \
5 -d '{}'
6Step 4.2: Creating the Custom Agent Class
The
MyVoiceAgent class extends the Agent class, defining the agent's behavior during session entry and exit. This is where you can customize the agent's initial and final interactions with users.1class MyVoiceAgent(Agent):
2 def __init__(self):
3 super().__init__(instructions=agent_instructions)
4 async def on_enter(self): await self.session.say("Hello! How can I help?")
5 async def on_exit(self): await self.session.say("Goodbye!")
6Step 4.3: Defining the Core Pipeline
The
CascadingPipeline
is crucial for defining how the agent processes audio. It integrates STT, LLM, TTS, VAD, and the Turn Detector to create a seamless interaction flow.1pipeline = CascadingPipeline(
2 stt=DeepgramSTT(model="nova-2", language="en"),
3 llm=OpenAILLM(model="gpt-4o"),
4 tts=ElevenLabsTTS(model="eleven_flash_v2_5"),
5 vad=SileroVAD(threshold=0.35),
6 turn_detector=TurnDetector(threshold=0.8)
7)
8Step 4.4: Managing the Session and Startup Logic
The
start_session function initializes the agent session, connecting the conversation flow with the processing pipeline. The make_context function configures the room options, and the main block starts the job.1def make_context() -> JobContext:
2 room_options = RoomOptions(
3 # room_id="YOUR_MEETING_ID", # Set to join a pre-created room; omit to auto-create
4 name="VideoSDK Cascaded Agent",
5 playground=True
6 )
7 return JobContext(room_options=room_options)
8
9if __name__ == "__main__":
10 job = WorkerJob(entrypoint=start_session, jobctx=make_context)
11 job.start()
12Running and Testing the Agent
Step 5.1: Running the Python Script
Execute the Python script to start the agent:
1python main.py
2Step 5.2: Interacting with the Agent in the Playground
Once the script is running, you will see a playground link in the console. Use this link to join the session and interact with your agent. The agent will respond to your voice inputs in real-time.
Advanced Features and Customizations
Extending Functionality with Custom Tools
VideoSDK allows you to extend your agent's capabilities by integrating custom tools. This can include additional plugins or services to enhance the agent's functionality.
Exploring Other Plugins
While this tutorial uses specific plugins for STT, LLM, and TTS, VideoSDK supports various options. Explore alternatives to find the best fit for your needs.
Troubleshooting Common Issues
API Key and Authentication Errors
Ensure your API keys are correctly set in the
.env file. Double-check the authorization headers in your API requests.Audio Input/Output Problems
Verify your microphone and speaker settings. Ensure your system permissions allow audio access for the application.
Dependency and Version Conflicts
Use a virtual environment to manage dependencies. Ensure all installed packages are compatible with Python 3.11+.
Conclusion
Summary of What You've Built
In this tutorial, you built a low latency TTS AI Voice Agent using VideoSDK. The agent processes real-time user inputs and responds with minimal delay, providing a seamless interaction experience.
Next Steps and Further Learning
Explore additional VideoSDK features and plugins to enhance your agent. Consider integrating more advanced functionalities and customizations to tailor the agent to specific use cases. For a comprehensive understanding of the
AI voice Agent core components overview
, delve deeper into the documentation to expand your knowledge.Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ