Multimodal Agents: Building the Next Generation of Intelligent AI
Introduction to Multimodal Agents
What are Multimodal Agents?
Multimodal agents are intelligent systems designed to process and understand information from multiple modalities, such as text, images, audio, and sensor data. Unlike traditional AI systems that focus on a single type of input, multimodal agents leverage the richness of combined data streams to achieve a more comprehensive understanding of their environment and user intentions. This leads to more robust, adaptable, and human-like interactions.
The Rise of Multimodal AI
The field of multimodal AI is experiencing rapid growth, driven by advances in deep learning, increased availability of multimodal datasets, and the growing demand for more sophisticated AI applications. As AI systems become more integrated into our daily lives, the ability to understand and respond to the world in a nuanced, context-aware manner is becoming increasingly important. Multimodal AI agents are well-positioned to meet this demand by providing a more natural and intuitive way for humans to interact with technology, leveraging modalities like natural language processing (NLP) and computer vision.
Benefits of Multimodal Agents
The benefits of using multimodal agents are numerous. They can:
- Improve Accuracy: By integrating information from multiple sources, multimodal agents can achieve higher accuracy in tasks such as object recognition, sentiment analysis, and intent detection.
- Enhance Robustness: Multimodal systems are less susceptible to noise and errors in any single modality, making them more reliable in real-world scenarios.
- Enable Richer Interactions: Multimodal agents can engage in more natural and intuitive interactions with users, understanding their needs and preferences more effectively.
- Provide Context-Awareness: They can understand the context of a situation by considering various modalities, leading to more relevant and personalized responses. This ties closely into context-aware agent design.
Core Modalities in Multimodal Agents
Text Modality: NLP and Language Understanding
Text is a fundamental modality for communication and information processing. Natural Language Processing (NLP) techniques enable multimodal agents to understand, interpret, and generate human language. This involves tasks like sentiment analysis, named entity recognition, and machine translation.
python
1import nltk
2from nltk.sentiment import SentimentIntensityAnalyzer
3
4# Download necessary NLTK data (run this once)
5# nltk.download('vader_lexicon')
6
7sentiment_analyzer = SentimentIntensityAnalyzer()
8text = "This is an amazing and insightful blog post!"
9scores = sentiment_analyzer.polarity_scores(text)
10print(scores) # Output: {'neg': 0.0, 'neu': 0.408, 'pos': 0.592, 'compound': 0.8431}
11This code snippet uses NLTK's
SentimentIntensityAnalyzer to determine the sentiment of a given text. The output provides scores for negative, neutral, positive, and compound sentiment.Visual Modality: Computer Vision and Image Processing
Computer vision allows multimodal agents to "see" and interpret the visual world. This includes tasks such as image recognition, object detection, and image segmentation. By processing visual information, agents can understand the content of images and videos, enabling them to interact with the environment in a more meaningful way. Understanding the visual modality will become more relevant with the advent of robotic agents.
python
1import tensorflow as tf
2from tensorflow.keras.applications import MobileNetV2
3from tensorflow.keras.preprocessing import image
4import numpy as np
5
6# Load pre-trained MobileNetV2 model
7model = MobileNetV2(weights='imagenet')
8
9# Load and preprocess an image
10img_path = 'path/to/your/image.jpg' # Replace with the actual path
11img = image.load_img(img_path, target_size=(224, 224))
12x = image.img_to_array(img)
13x = np.expand_dims(x, axis=0)
14x = tf.keras.applications.mobilenet_v2.preprocess_input(x)
15
16# Make a prediction
17predictions = model.predict(x)
18decoded_predictions = tf.keras.applications.mobilenet_v2.decode_predictions(predictions, top=3)[0]
19
20print('Predictions:')
21for i, (imagenet_id, label, score) in enumerate(decoded_predictions):
22 print(f'{i + 1}: {label} ({score:.2f})')
23This example demonstrates how to use a pre-trained MobileNetV2 model in TensorFlow/Keras for image classification. It loads an image, preprocesses it, and then predicts the top 3 most likely classes.
Auditory Modality: Speech Recognition and Audio Processing
Speech recognition enables multimodal agents to understand spoken language. This involves converting audio signals into text, allowing the agent to respond to voice commands and engage in spoken conversations. Audio processing also includes tasks such as speaker identification, emotion recognition from speech, and environmental sound classification.
Tactile and Other Modalities
Beyond text, vision, and audio, multimodal agents can also incorporate other modalities, such as tactile feedback (haptic sensing), temperature, pressure, and even physiological signals. For example, a robotic agent might use tactile sensors to manipulate objects with greater precision, or a healthcare application could monitor a patient's heart rate and skin conductance to detect signs of stress.
Architectures and Technologies for Multimodal Agents
Multimodal Data Fusion Techniques
Multimodal data fusion is the process of integrating information from multiple modalities into a unified representation. This is a crucial step in building effective multimodal agents. Common techniques include:
- Early Fusion: Concatenating features from different modalities at the input level.
- Late Fusion: Making independent predictions for each modality and then combining them at the decision level.
- Intermediate Fusion: Fusing modalities at intermediate layers of a deep learning model.
Choosing the right fusion technique depends on the specific application and the characteristics of the data. Early fusion is suitable when the modalities are highly correlated, while late fusion is more appropriate when the modalities are independent.
Deep Learning Models for Multimodal Agents
Deep learning models have proven to be highly effective for multimodal agent development. Some popular architectures include:
- Recurrent Neural Networks (RNNs): Useful for processing sequential data such as text and audio.
- Convolutional Neural Networks (CNNs): Effective for image and video processing.
- Transformers: Well-suited for handling long-range dependencies in text and other modalities. Attention mechanisms are useful for determining which parts of each modality are most relevant for the task at hand.
- Graph Neural Networks (GNNs): For modeling relationships between entities in different modalities.
These models can be combined and customized to create powerful multimodal agents capable of complex tasks. The choice of architecture depends on the specific modalities and the desired functionality of the agent.
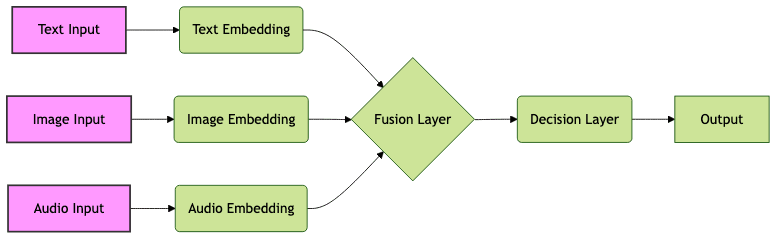
This diagram illustrates a basic multimodal architecture with text, image, and audio inputs, which are processed into embeddings and fused before a final decision is made.
Reinforcement Learning for Multimodal Agent Training
Reinforcement learning (RL) can be used to train multimodal agents to perform complex tasks in dynamic environments. The agent learns through trial and error, receiving rewards for taking actions that lead to desired outcomes. RL is particularly useful for training agents that need to make sequential decisions based on multimodal input, such as robotic agents that need to navigate and interact with their surroundings.
Applications of Multimodal Agents
Customer Service and Chatbots
Multimodal chatbots can provide more personalized and efficient customer service by understanding not only text-based queries but also visual cues and voice intonation. This allows them to better understand customer needs and provide more relevant responses, improving customer satisfaction.
Healthcare and Medical Diagnosis
Multimodal agents can assist healthcare professionals in diagnosing diseases by analyzing medical images, patient history, and other relevant data. For example, they can analyze X-rays and MRIs, combined with patient symptoms, to detect anomalies and suggest potential diagnoses. Multi-modal AI can become a vital tool in medical facilities.
Education and Personalized Learning
Multimodal agents can create personalized learning experiences by adapting to individual student needs and learning styles. They can analyze student performance, engagement, and emotional state to provide tailored instruction and feedback. The incorporation of NLP, computer vision, and speech recognition will provide unique personalized experiences.
Robotics and Autonomous Systems
Multimodal agents are essential for enabling robots and autonomous systems to operate in complex and unstructured environments. By integrating data from sensors, cameras, and other sources, these agents can perceive their surroundings, make informed decisions, and interact with humans in a safe and effective manner. This contributes towards the development of embodied agent systems.
Challenges and Future Directions
Data Scarcity and Bias
A significant challenge in developing multimodal agents is the scarcity of high-quality, labeled multimodal datasets. Furthermore, biases present in the data can lead to unfair or discriminatory outcomes. Addressing these issues requires careful data collection and annotation, as well as the development of techniques for mitigating bias in machine learning models.
Computational Cost and Scalability
Processing multiple modalities can be computationally expensive, especially for deep learning models. This can limit the scalability of multimodal agents, making it difficult to deploy them in resource-constrained environments. Future research needs to focus on developing more efficient algorithms and hardware architectures for multimodal processing.
Explainability and Trustworthiness
As AI systems become more complex, it is increasingly important to understand how they make decisions. Explainable AI (XAI) techniques are needed to provide insights into the reasoning processes of multimodal agents, making them more transparent and trustworthy. This is particularly important in high-stakes applications such as healthcare and autonomous driving.
Ethical Considerations
The development and deployment of multimodal agents raise a number of ethical considerations, including privacy, security, and fairness. It is crucial to address these issues proactively to ensure that these technologies are used responsibly and ethically. This is an important factor when considering AI ethics.
Conclusion
Multimodal agents represent a significant step forward in the development of intelligent AI systems. By integrating information from multiple modalities, these agents can achieve a more comprehensive understanding of the world and interact with humans in a more natural and intuitive way. While challenges remain, the potential benefits of multimodal AI are vast, promising to transform industries ranging from customer service to healthcare to robotics. Understanding how to create a proper multimodal architecture will greatly benefit new AI initiatives.
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ